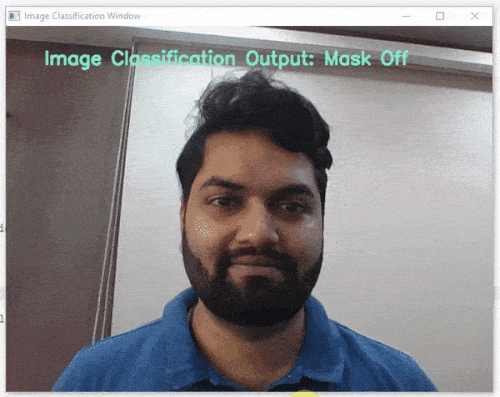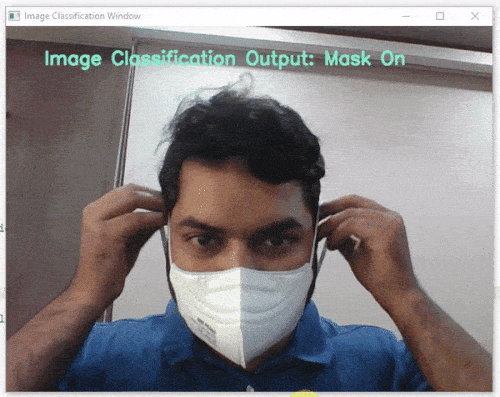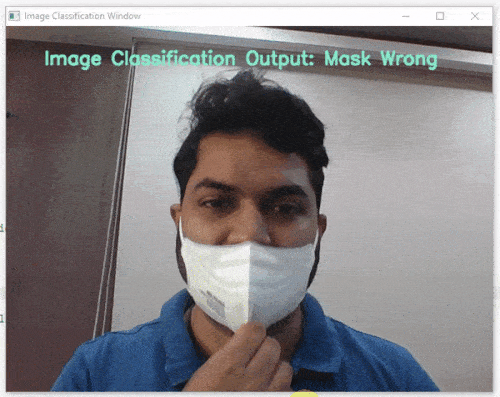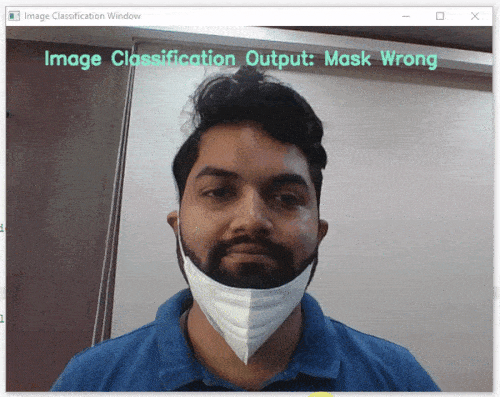
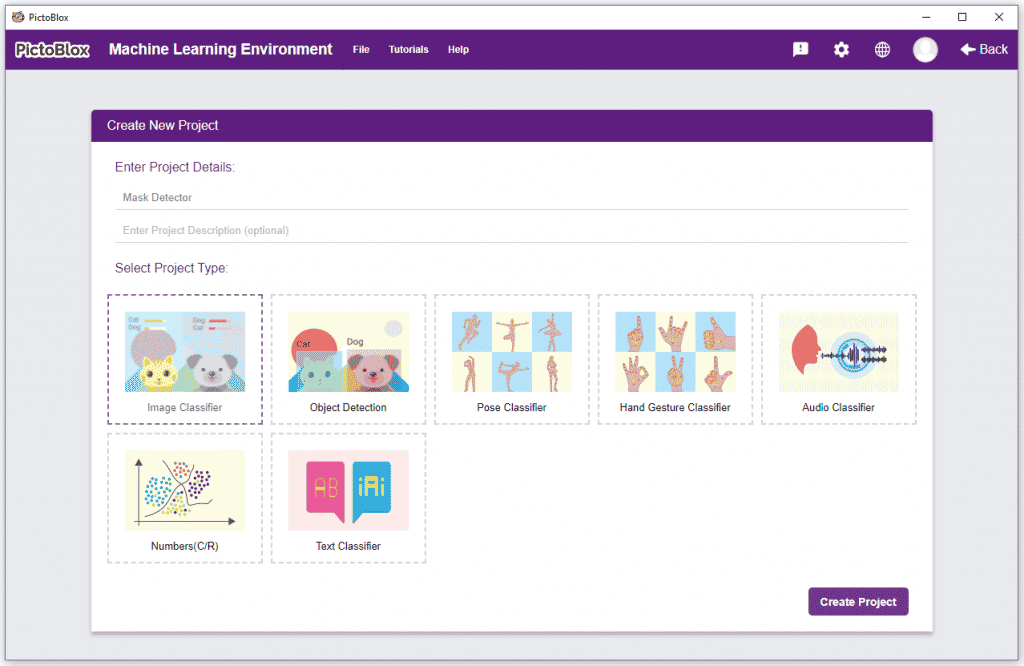
Image Classifier is the extension of the ML Environment that deals with the classification of the images into different classes.
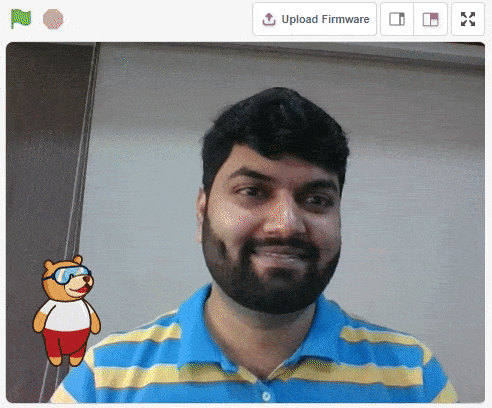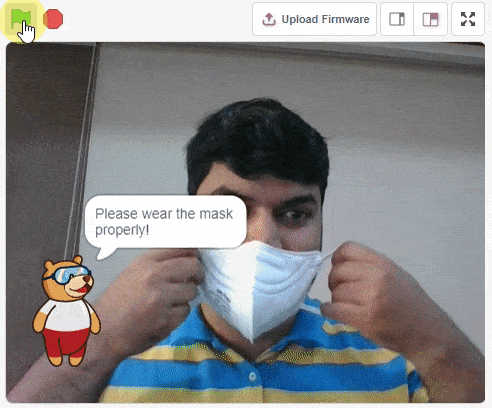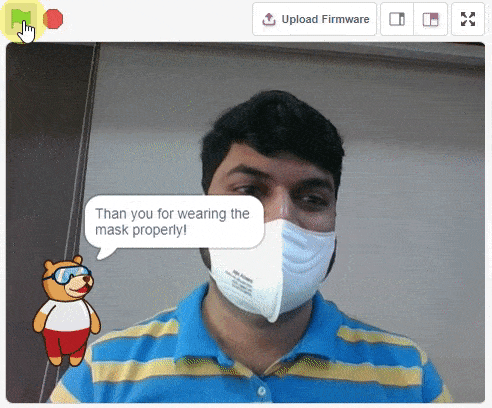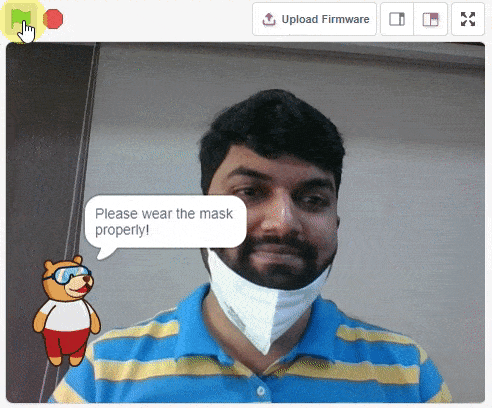
For example, let’s say you want to construct a model to judge if a person is wearing a mask correctly or not, or if the person’s wearing one at all.
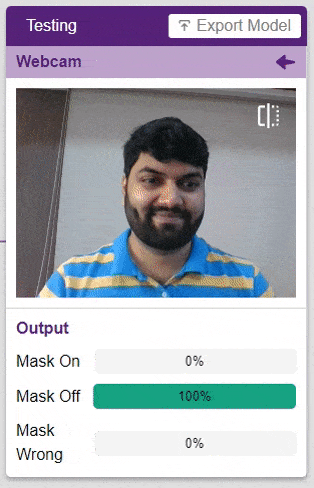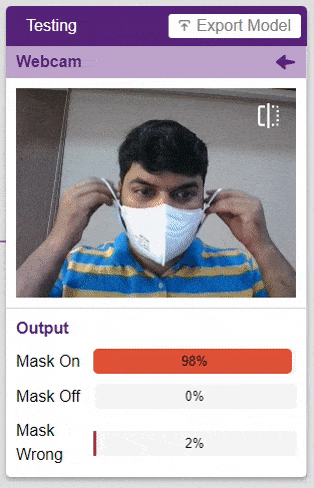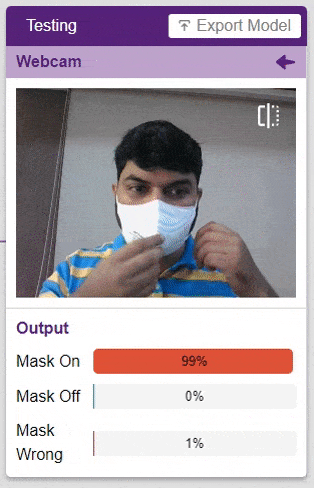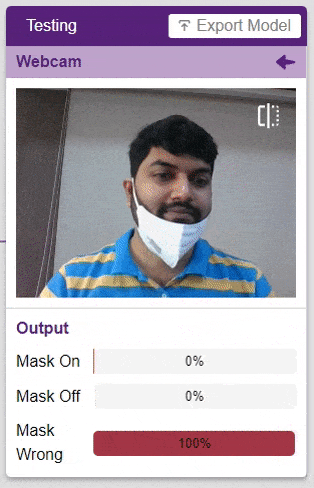
This is the case of image classification where you want the machine to label the images into one of the classes.

Follow the steps below:
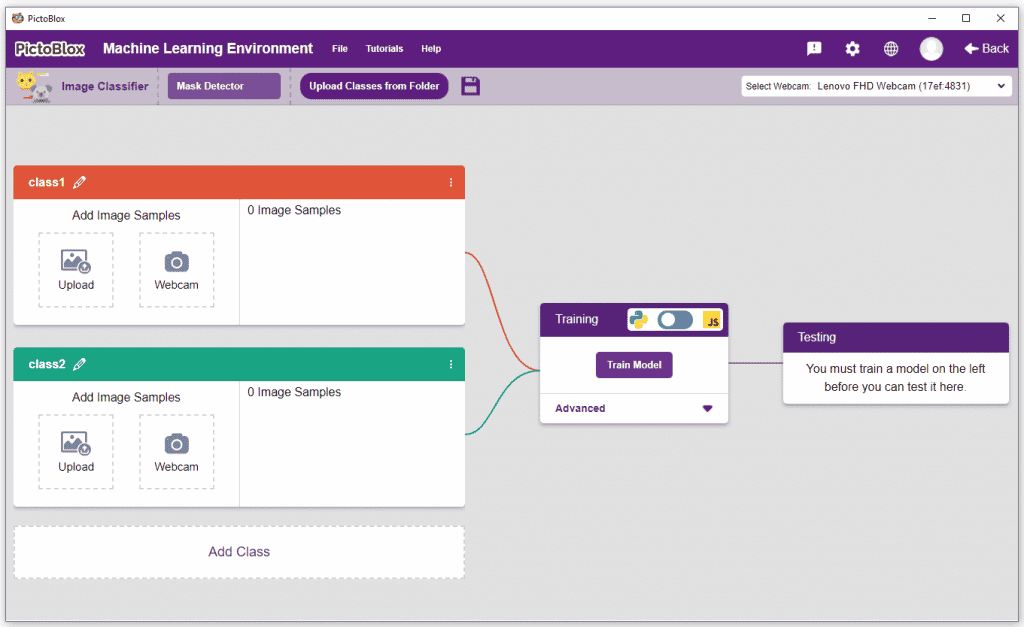
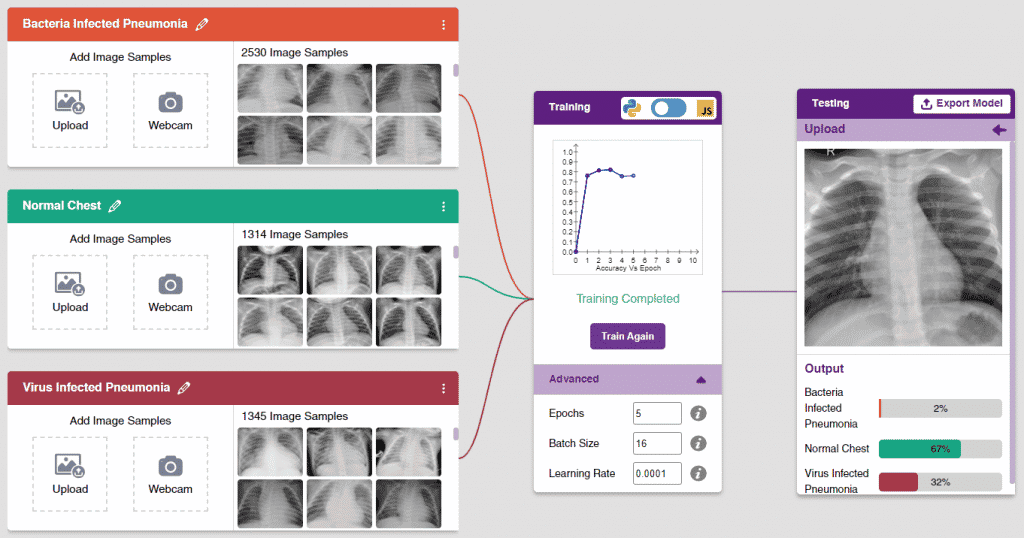
Class is the category in which the Machine Learning model classifies the images. Similar images are put in one class.
There are 2 things that you have to provide in a class:


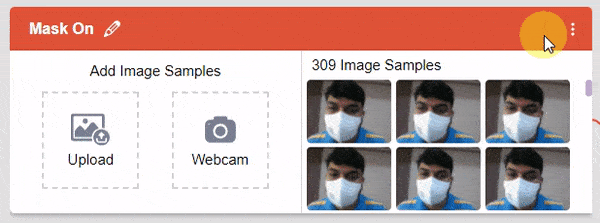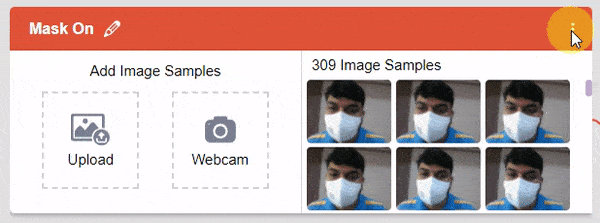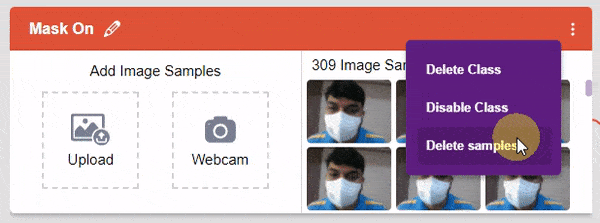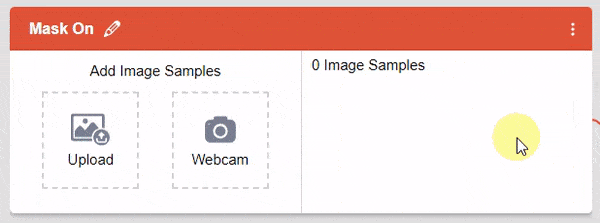
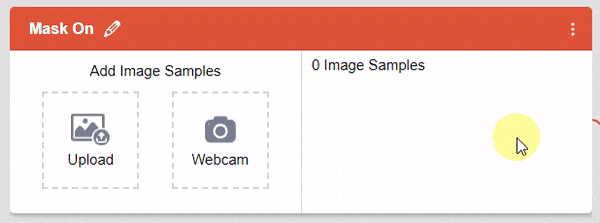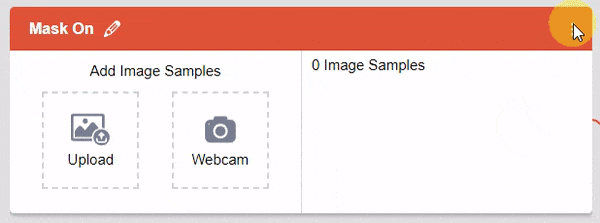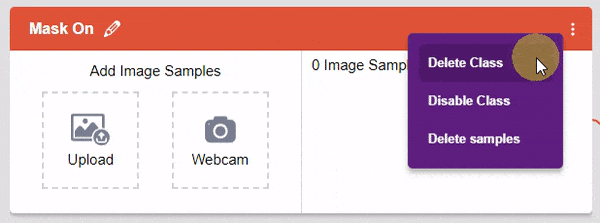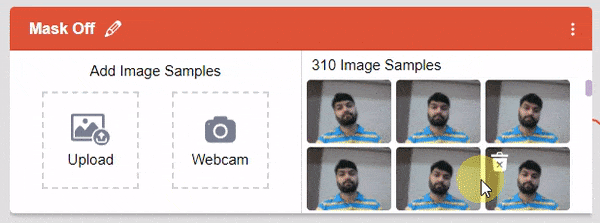
You can perform the following operations to manipulate the data into a class.
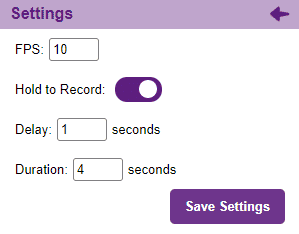
If you want to change your camera feed, you can do it from the webcam selector in the top right corner.
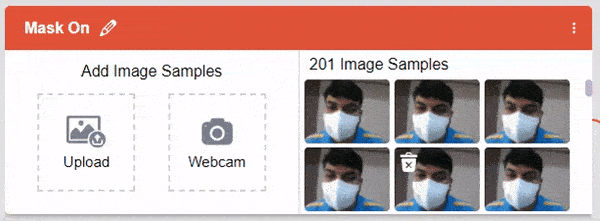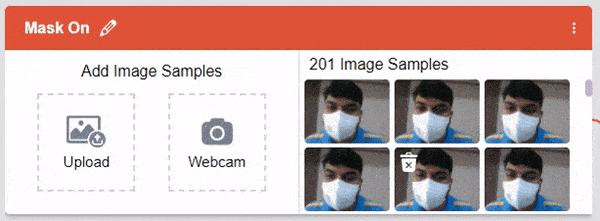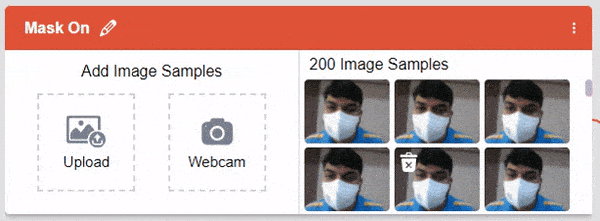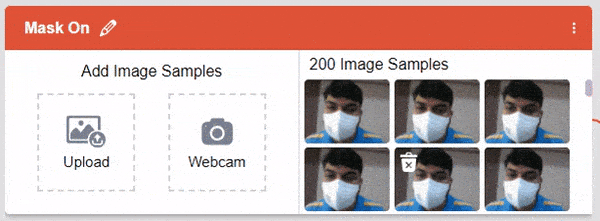
After data is added, it’s fit to be used in model training. In order to do this, we have to train the model. By training the model, we extract meaningful information from the images, and that in turn updates the weights. Once these weights are saved, we can use our model to make predictions on data previously unseen.
However, before training the model, there are a few hyperparameters that you should be aware of. Click on the “Advanced” tab to view them.
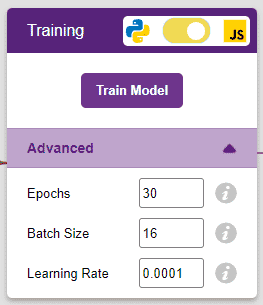
There are three hyperparameters you can play along with here:
It’s a good idea to train a numeric classification model for a high number of epochs. The model can be trained in both JavaScript and Python. In order to choose between the two, click on the switch on top of the Training panel.
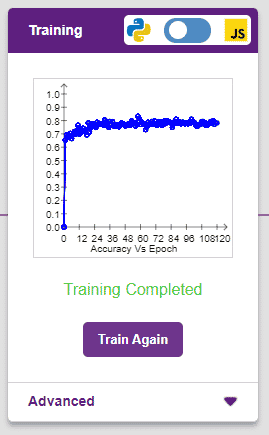
The accuracy of the model should increase over time. The x-axis of the graph shows the epochs, and the y-axis represents the accuracy at the corresponding epoch. Remember, the higher the reading in the accuracy graph, the better the model. The x-axis of the graph shows the epochs, and the y-axis represents the corresponding accuracy. The range of the accuracy is 0 to 1.
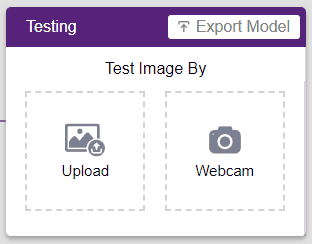
To test the model, simply enter the input values in the “Testing” panel and click on the “Predict” button.
The model will return the probability of the input belonging to the classes.
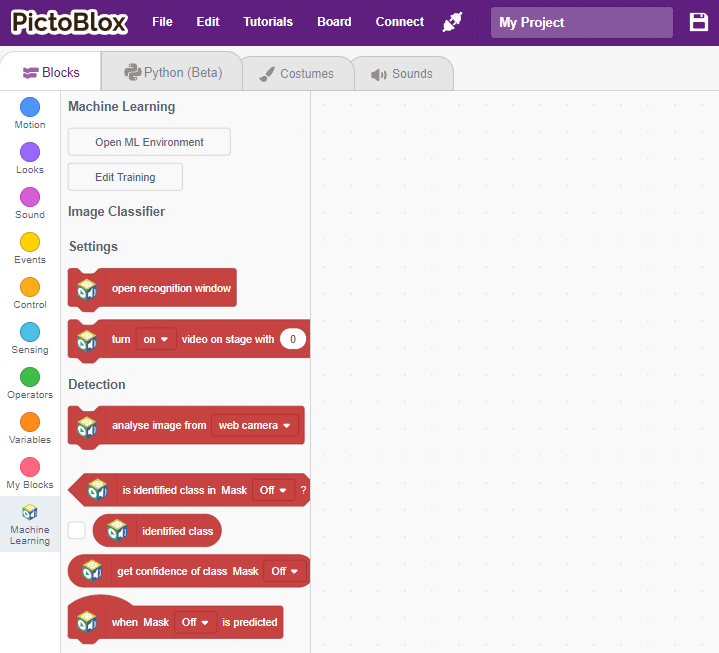
Click on the “Export Model” button on the top right of the Testing box, and PictoBlox will load your model into the Block Coding Environment if you have opened the ML Environment in the Block Coding.

Click on the “Export Model” button on the top right of the Testing box, and PictoBlox will load your model into the Python Coding Environment if you have opened the ML Environment in Python Coding.
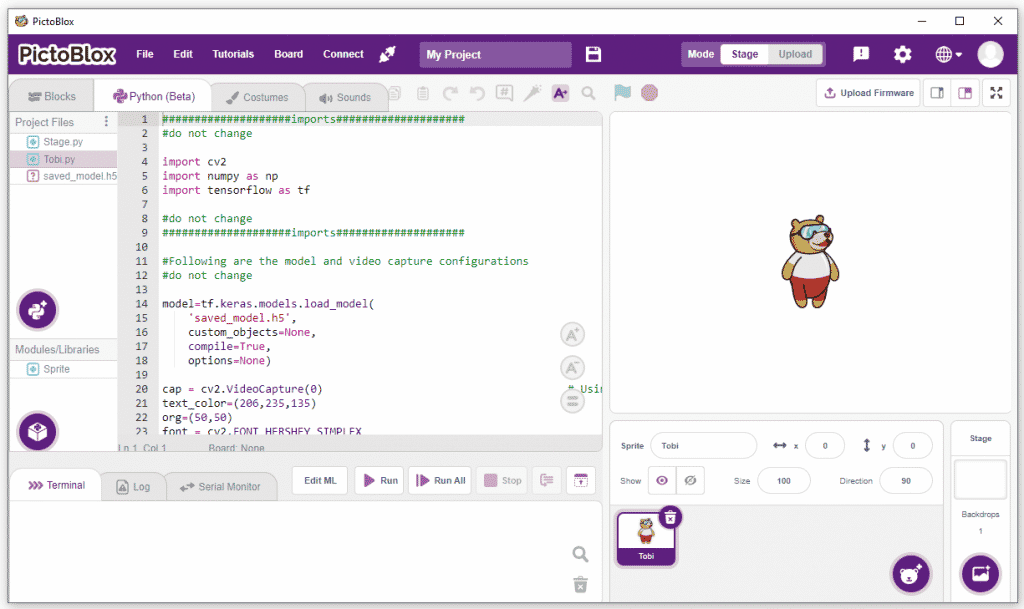
The following code appears in the Python Editor of the selected sprite.
####################imports####################
# Do not change
import cv2
import numpy as np
import tensorflow as tf
# Do not change
####################imports####################
#Following are the model and video capture configurations
# Do not change
model = tf.keras.models.load_model('saved_model.h5',
custom_objects=None,
compile=True,
options=None)
cap = cv2.VideoCapture(0) # Using device's camera to capture video
text_color = (206, 235, 135)
org = (50, 50)
font = cv2.FONT_HERSHEY_SIMPLEX
fontScale = 1
thickness = 3
class_list = ['Mask Off', 'Mask On', 'Mask Wrong'] # List of all the classes
# Do not change
###############################################
#This is the while loop block, computations happen here
while True:
ret, image_np = cap.read() # Reading the captured images
image_np = cv2.flip(image_np, 1)
image_resized = cv2.resize(image_np, (224, 224))
img_array = tf.expand_dims(image_resized,
0) # Expanding the image array dimensions
predict = model.predict(
img_array) # Making an initial prediction using the model
predict_index = np.argmax(predict[0],
axis=0) # Generating index out of the prediction
predicted_class = class_list[
predict_index] # Tallying the index with class list
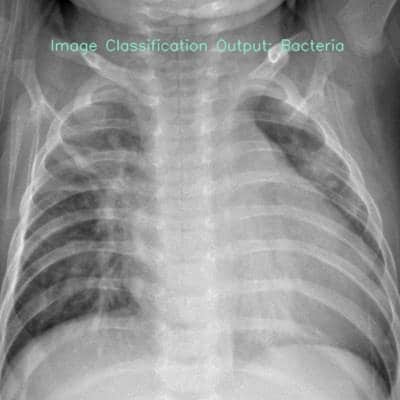
image_np = cv2.putText(
image_np, "Image Classification Output: " + str(predicted_class), org,
font, fontScale, text_color, thickness, cv2.LINE_AA)
cv2.imshow("Image Classification Window",
image_np) # Displaying the classification window
if cv2.waitKey(25) & 0xFF == ord(
'q'): # Press 'q' to close the classification window
break
cap.release() # Stops taking video input
cv2.destroyAllWindows() # Closes input window