
Tutorial Video
About Object Detection
The Object Detection extension of the PictoBlox Machine Learning Environment is used to detect the objects present in a given picture.
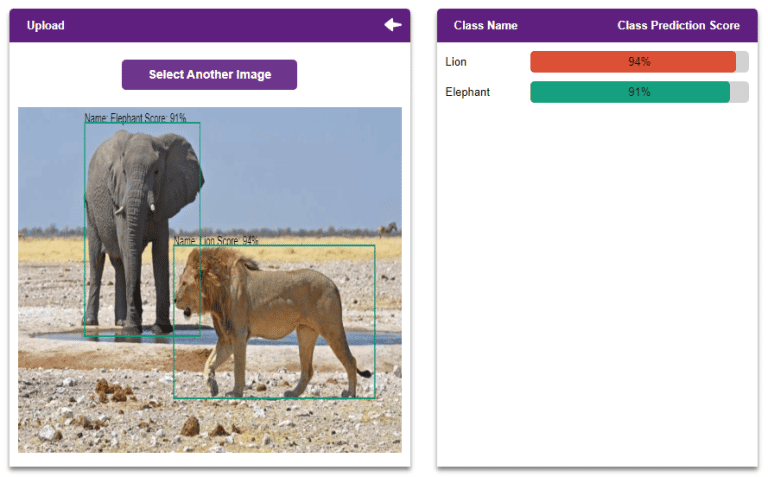
To train an Object Detection model, we need to ensure that the training samples are annotated. That is, target objects are enclosed in bounding boxes, and each bounding box is labeled with the corresponding class.
For this project, we’ll be constructing a model that can identify three different Quarky robot configurations:

- The Mars Rover
- The Pick and Place Robot
- The Humanoid Robot

The steps required in this project are as follows:
- Setting up the environment
- Gathering the data(Data collection)
- Annotating the data
- Training the model
- Evaluating the model
- Testing the model
- Exporting the model to PictoBlox Python
- Creating a python code in PictoBlox
Opening Image Classifier Workflow

Follow the steps below:
- Open PictoBlox and create a new file.
- Select the appropriate Coding Environment.
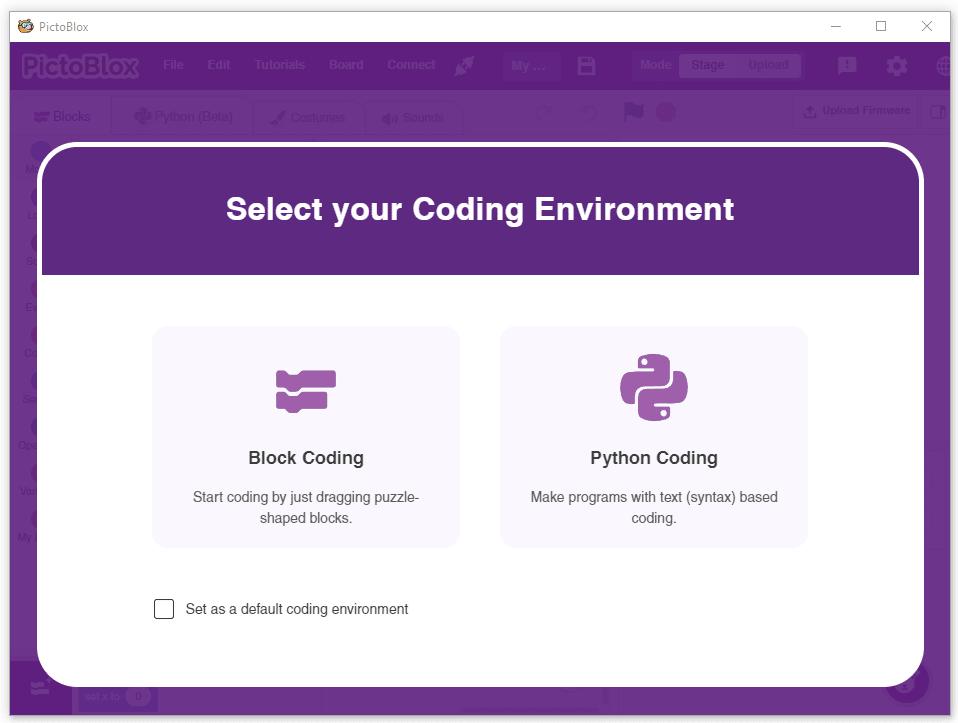
- Select the “Open ML Environment” option under the “Files” tab to access the ML Environment.
- You’ll be greeted with the following screen.
- You have to download the Python Dependencies for execution for the first time. If already done you can ignore it.
- Click on Download Dependencies from the setting sign on the top right.
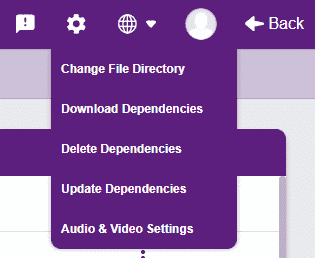
- The following model will open. Click on the Download button and wait for the dependencies to download.

- Click on Download Dependencies from the setting sign on the top right.
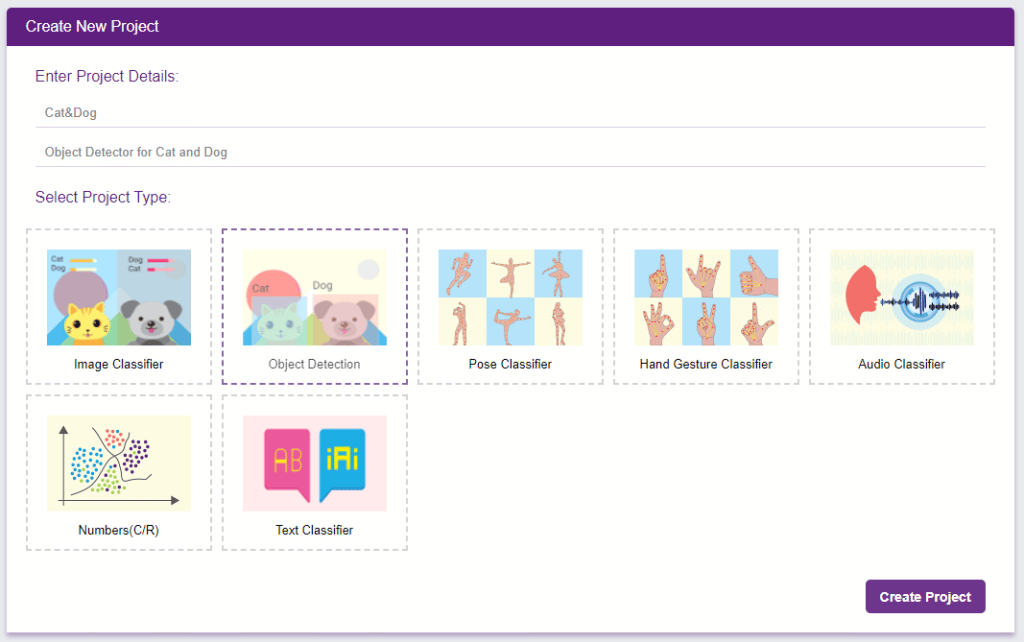
- Click on “Create New Project“.
- A window will open. Type in a project name of your choice and select the “Object Detection” extension. Click the “Create Project” button to open the Object Detection window.
- You shall see the Object Detection workflow with two classes already made for you. Your environment is all set. Now it’s time to upload the data.
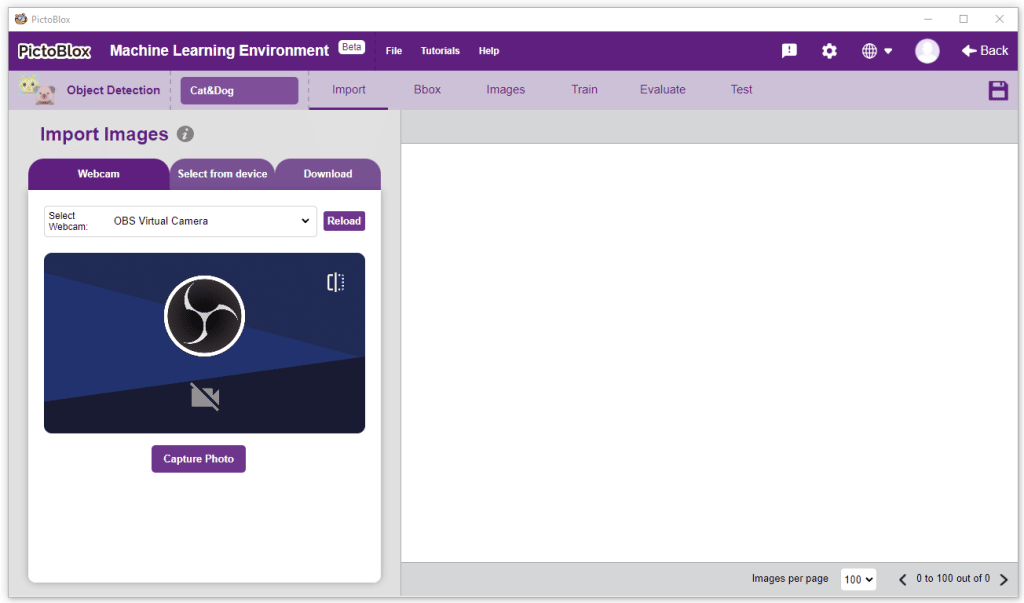
Collecting and Uploading the Data
The left side panel will give you three options to gather images:
- Using the Webcam to capture images.
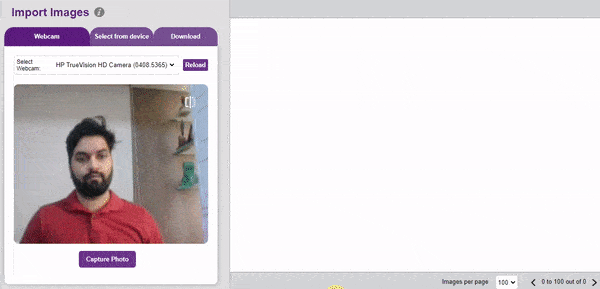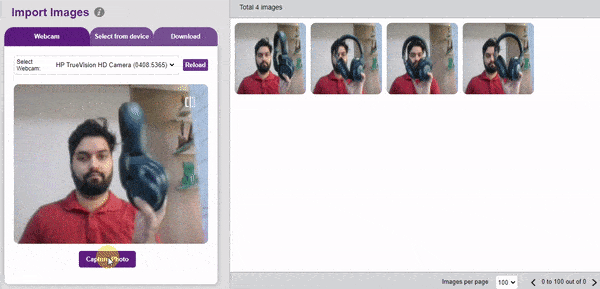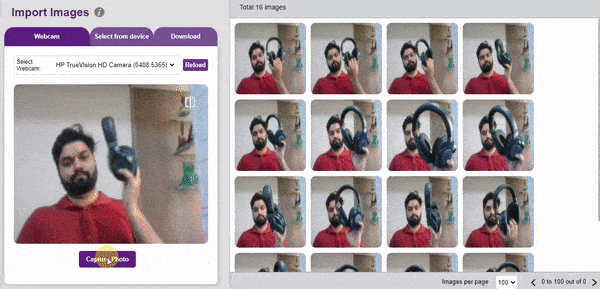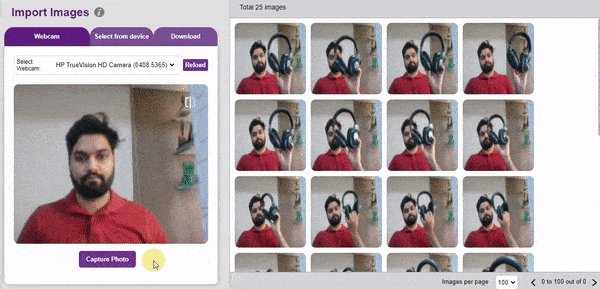
- Upload images from your device’s hard drive.
- Downloading from PictoBlox Database: This gives you the option of downloading pre-annotated images and annotating images captured manually by the user.
For this project, we’ll be making use of a dataset based on three Quraky-based robots: Quarky Optimized – Dataset
- The Mars Rover
- The Pick and Place Robot
- The Humanoid Robot
To import the images, click on the Webcam option and import all the images from the testing folder.
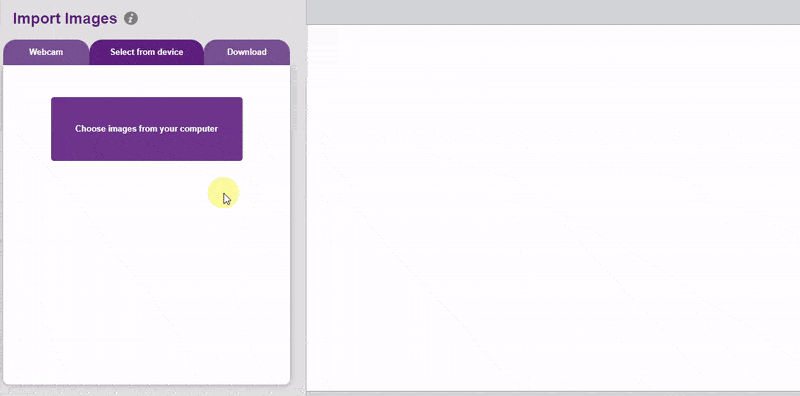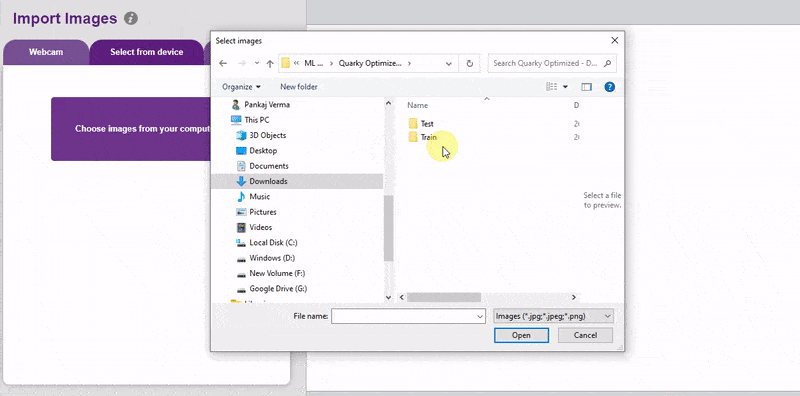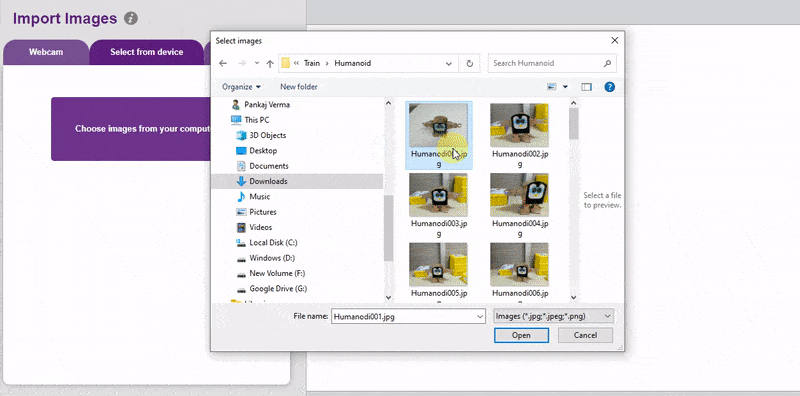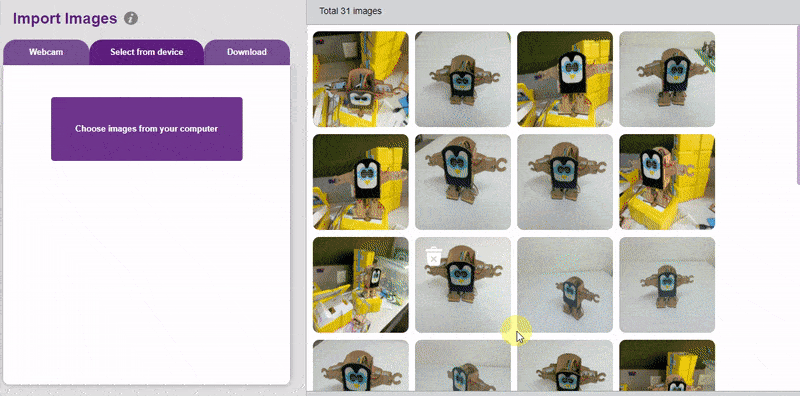
Now that we have our images ready, let’s annotate them to prepare our final dataset.
Annotating the Data
A bounding box is a rectangular box that can be drawn around an object in an image. Bounding boxes are used in object detection algorithms to identify objects in images.
We draw these rectangles over images, outlining the object of interest within each image by defining its X and Y coordinates. This makes it easier for machine learning algorithms to find what they’re looking for, determine collision paths, and conserves valuable computing resources.
Object detection has two components: object classification and object localization. In other words, to detect an object in an image, the computer needs to know what it is and where it is.
Follow the process:
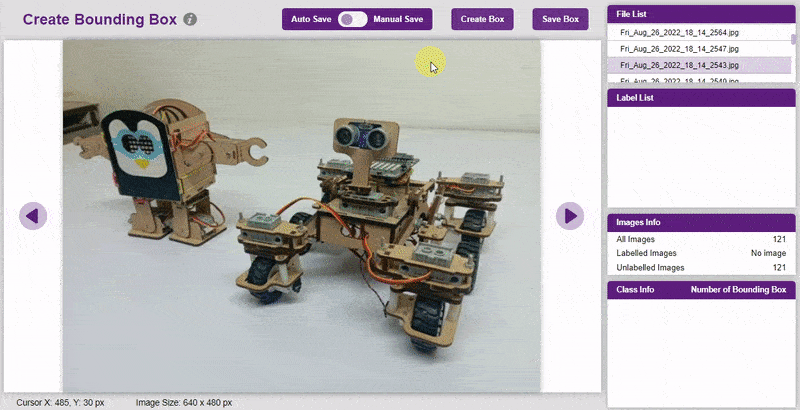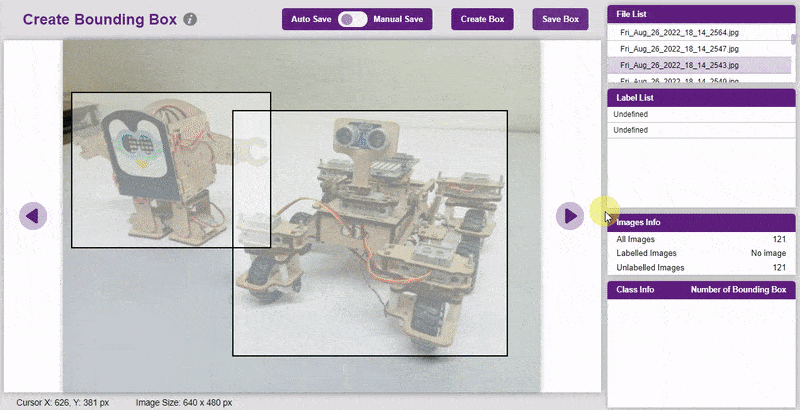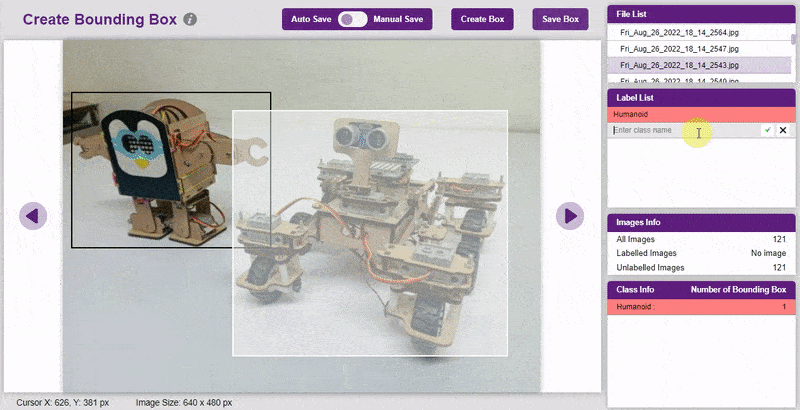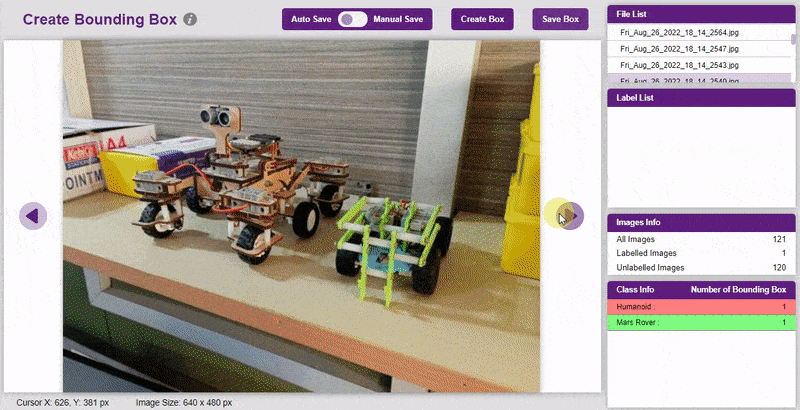
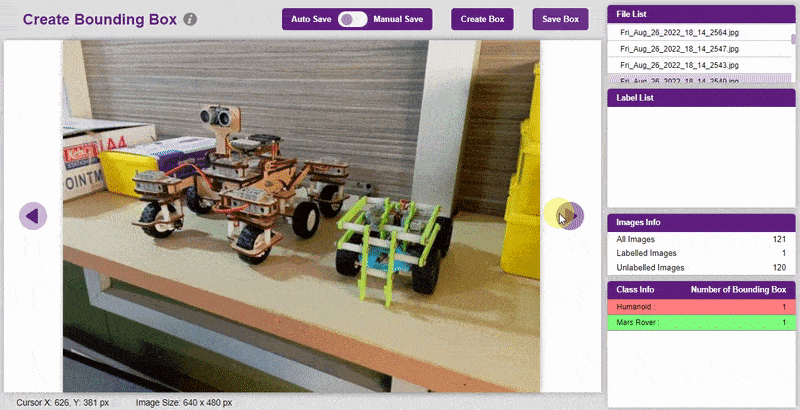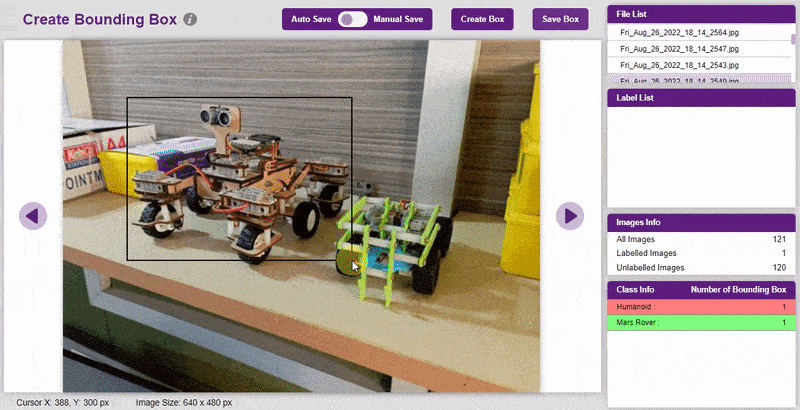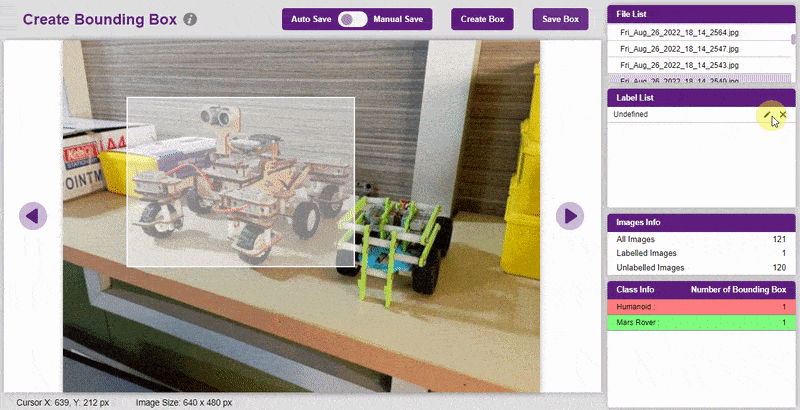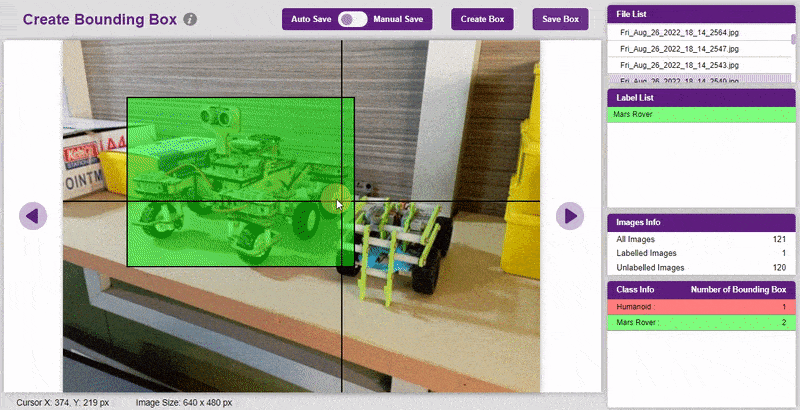
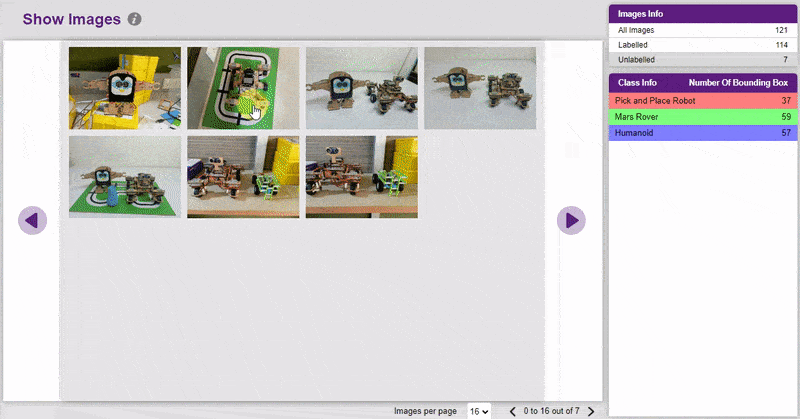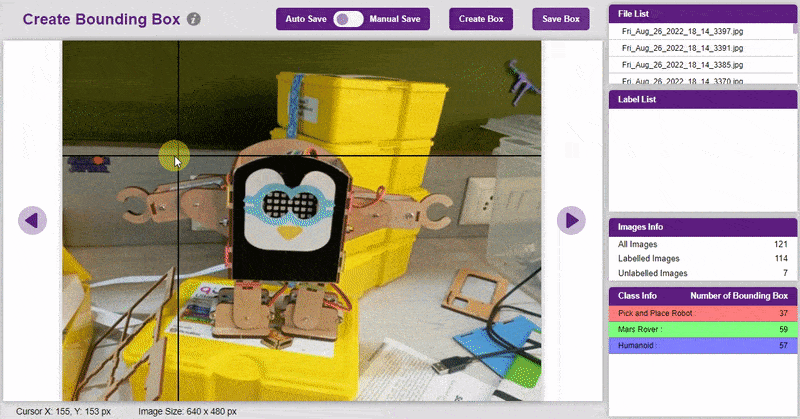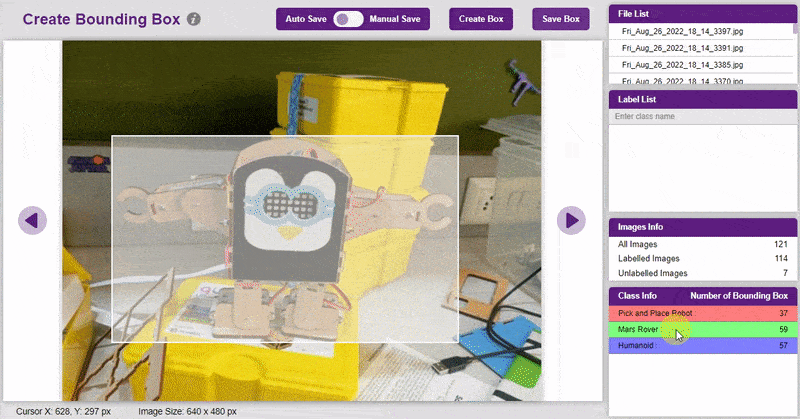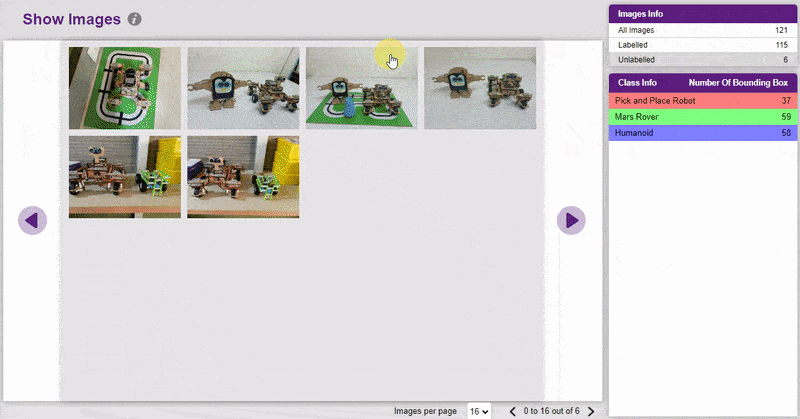
- Go to the “Bbox” tab to access it.
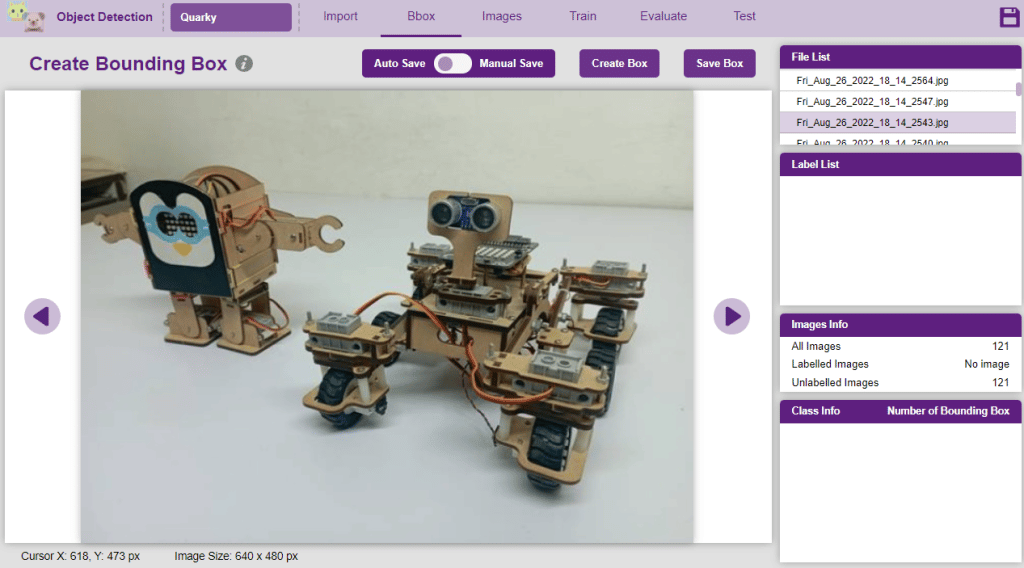
- To create the bounding box in the images, click on the “Create Box” button, to create a bounding box. After the box is drawn, go to the “Label List” column and click on the edit button, and type in a name for the object under the bounding box. This name will become a class. Once you’ve entered the name, click on the tick mark to label the object.
The object will be color coded as soon as you label it. - Once you’ve labeled an object, its count is updated in the “Class Info” column. You can simply click on the class to classify another object under that label.
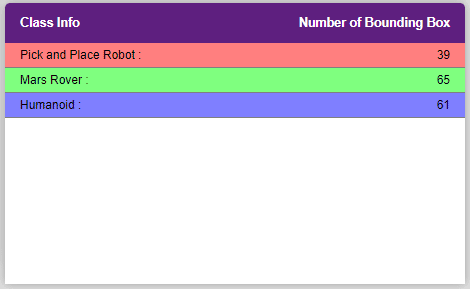
- Once you’ve labeled an object, its count is updated in the “Class Info” column. You can simply click on the class to classify another object under that label.
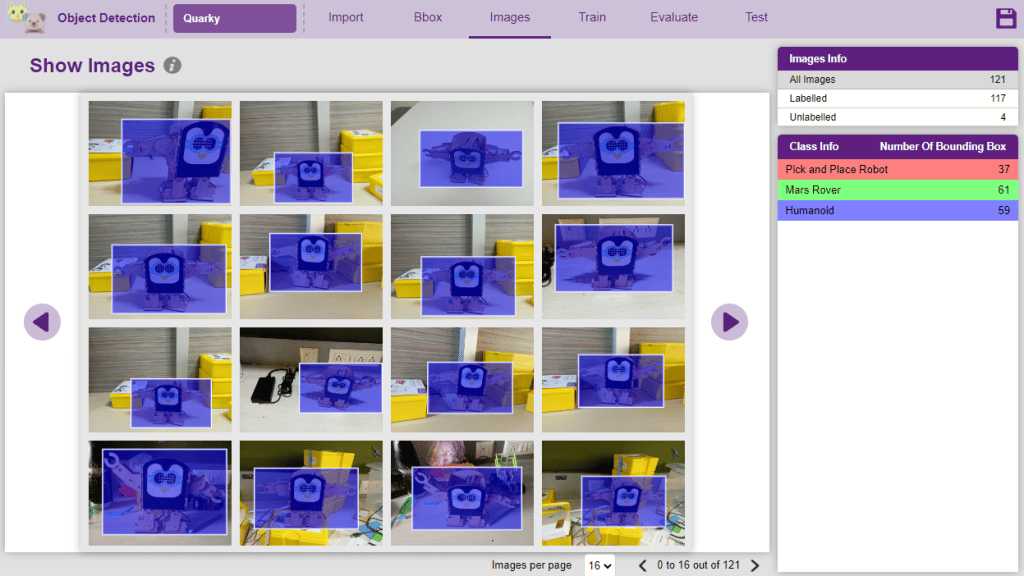
- You can view all the images under the “Image” tab.
- You can find the Unlabelled images in the tab and you can click on the image to add the label.
Training the Model
In Object Detection, the model must locate and identify all the targets in the given image. This makes Object Detection a complex task to execute. Hence, the hyperparameters work differently in the Object Detection Extension.
Follow the process:
- Go to the “Train” tab.
- Click on the “Train New Model” button. Select the classes that need to be trained, and click on “Generate Dataset”. Once the dataset is generated, click “Next”.
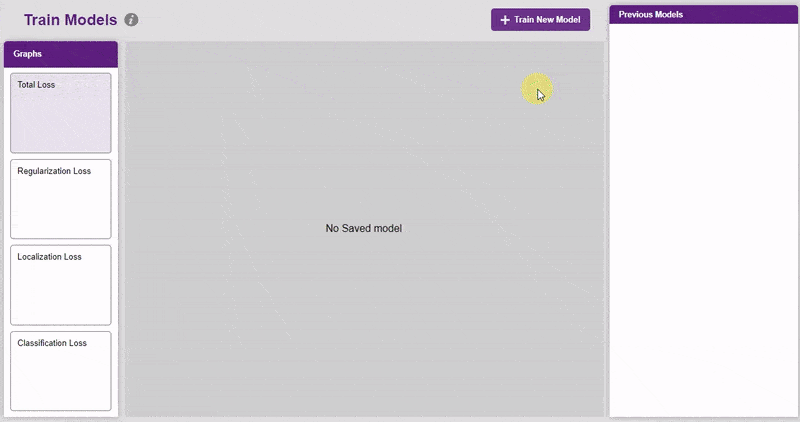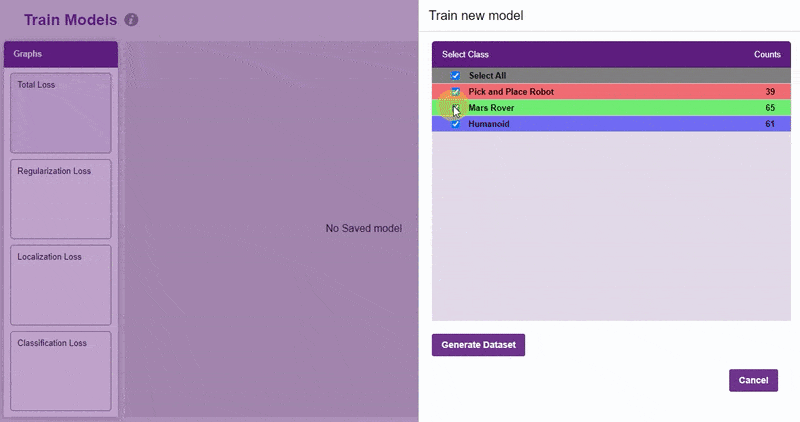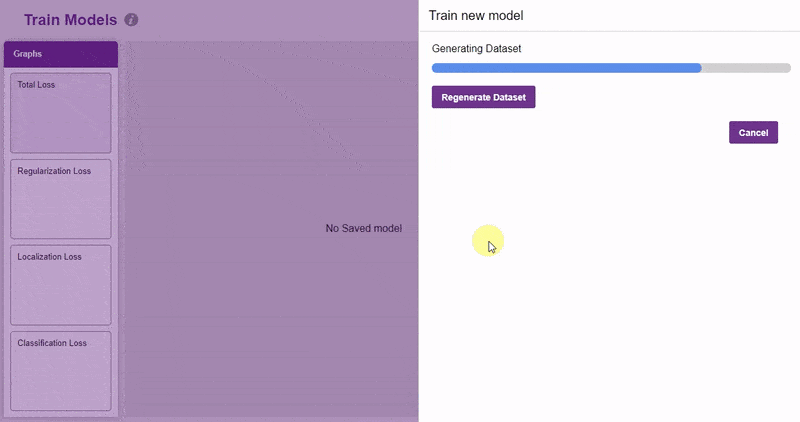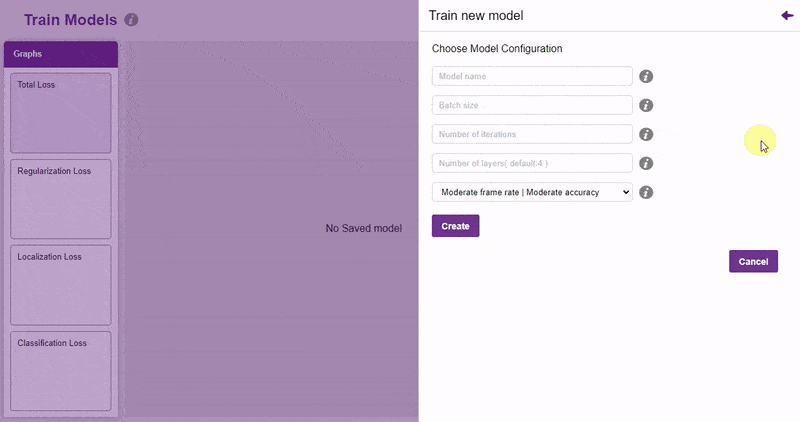
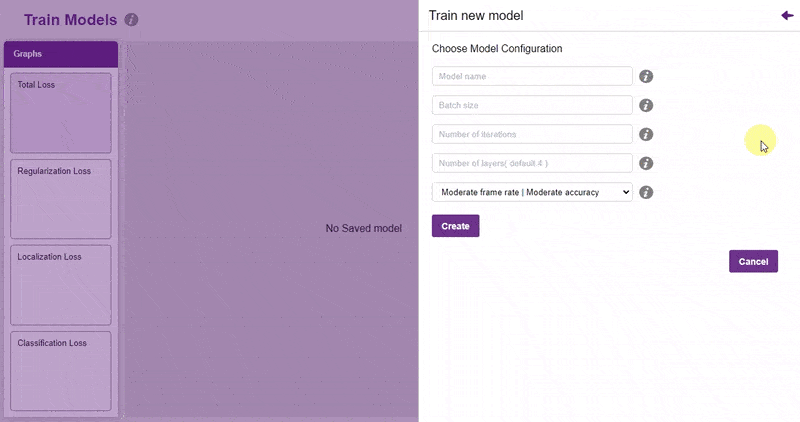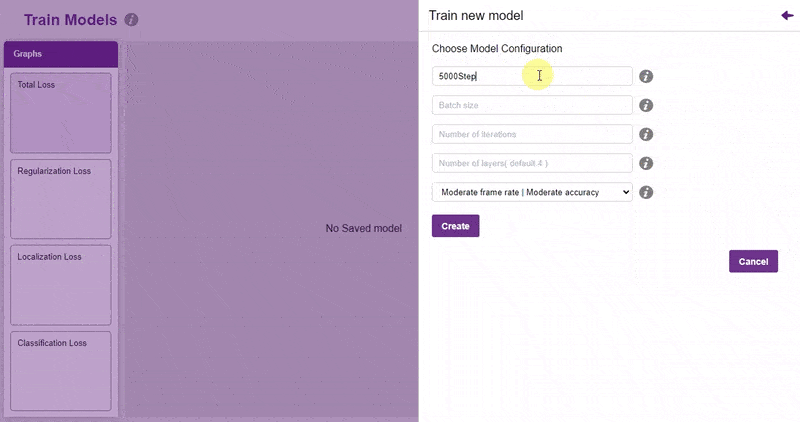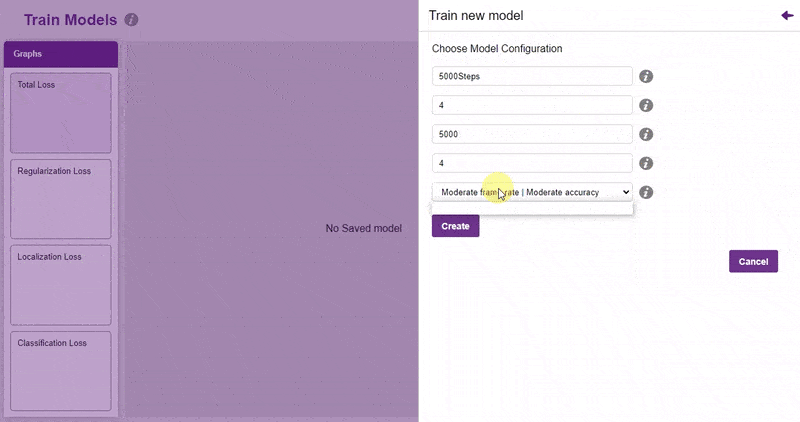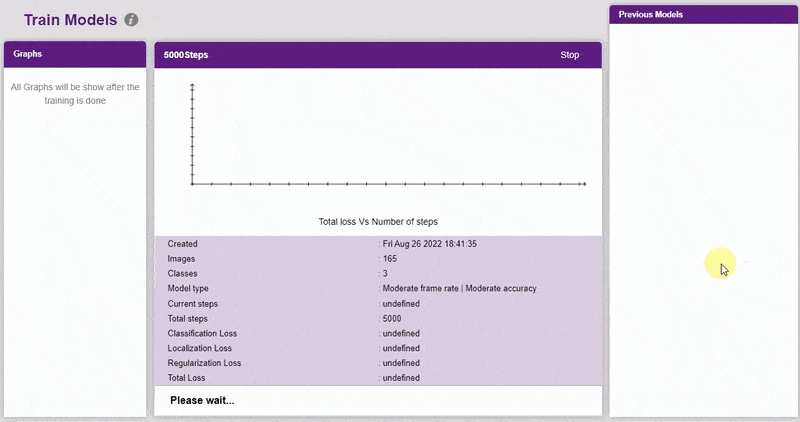
- You shall see the training configurations. Observe the hyperparameters.
- Model name – The name of the model.
- Batch size – The number of training samples utilized in one iteration. The larger the batch size, the larger the RAM required.
- Number of iterations – The number of times your model will iterate through a batch of images.
- Number of layers – The number of layers in your model. Use more layers for large models.
- Specify your hyperparameters. If the numbers go out of range, PictoBlox will show a message. Click “Create”.
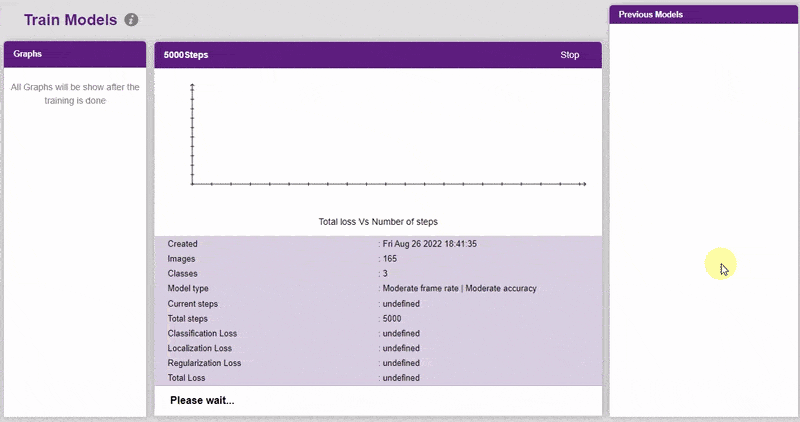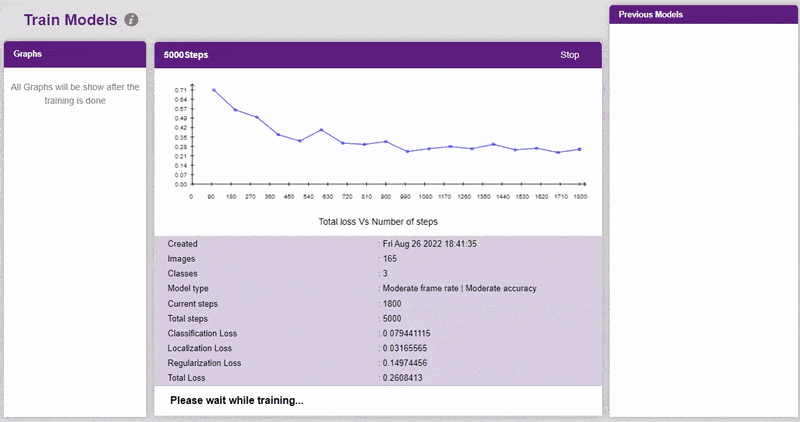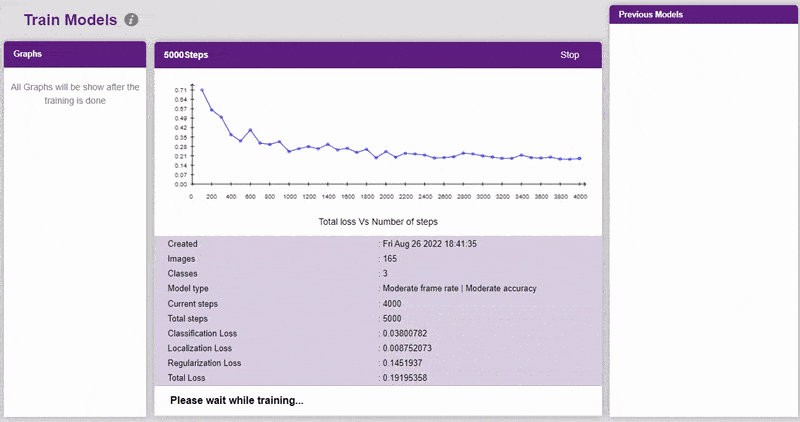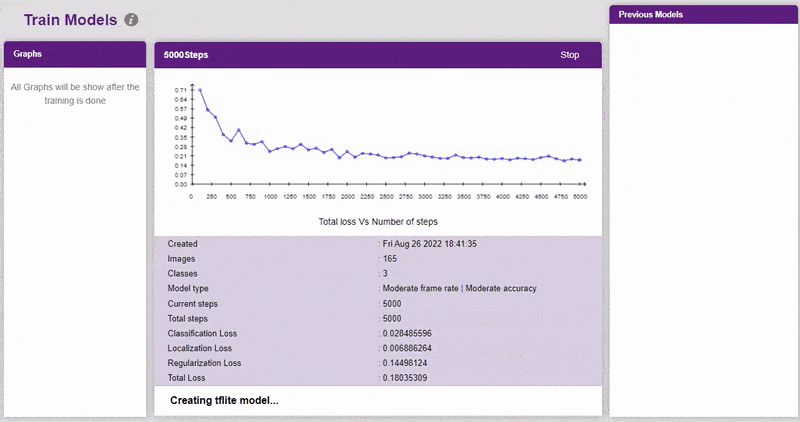
Evaluating the Model
Now, let’s move to the “Evaluate” tab. You can view True Positives, False Negatives, and False Positives for each class here along with metrics like Precision and Recall.
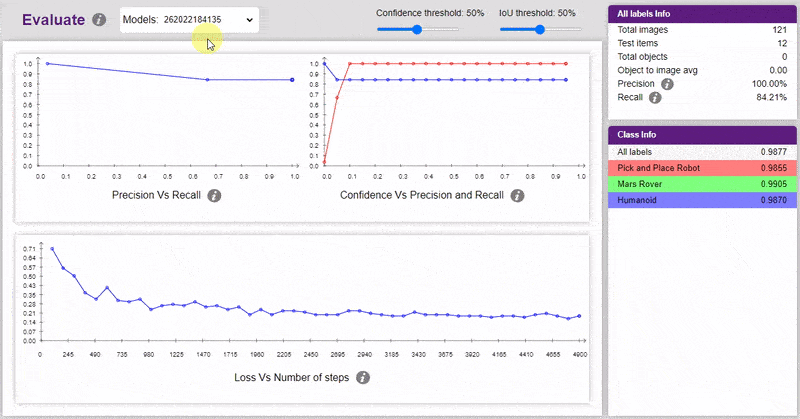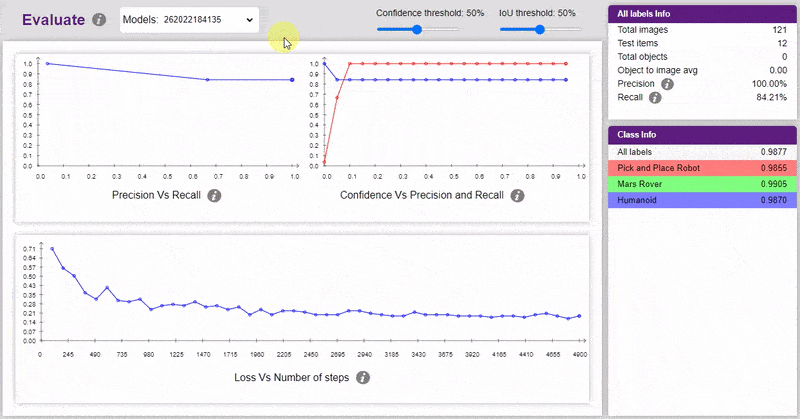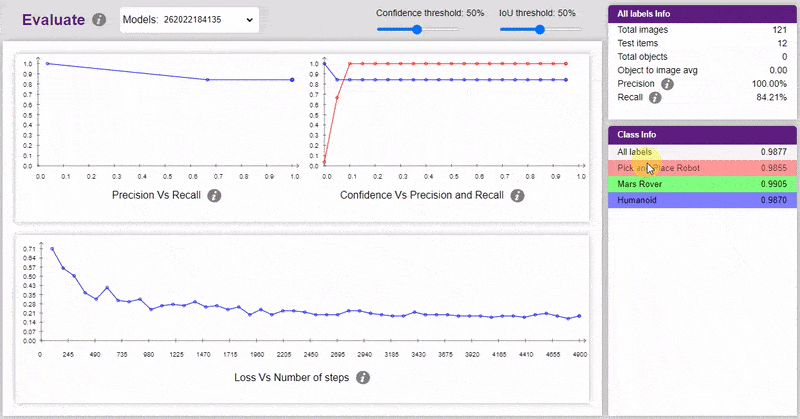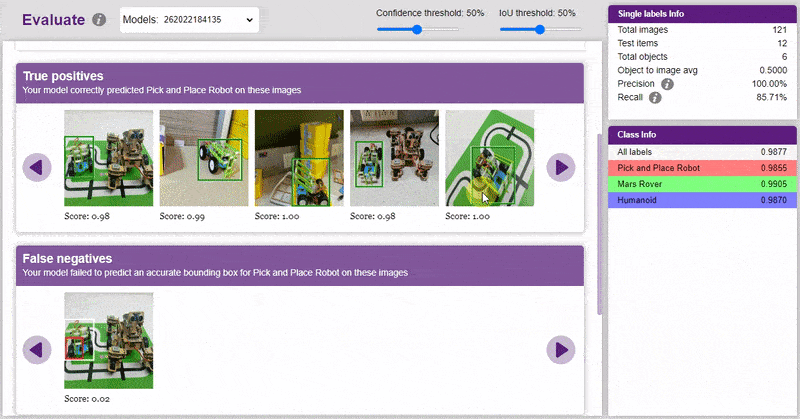
Testing the Model
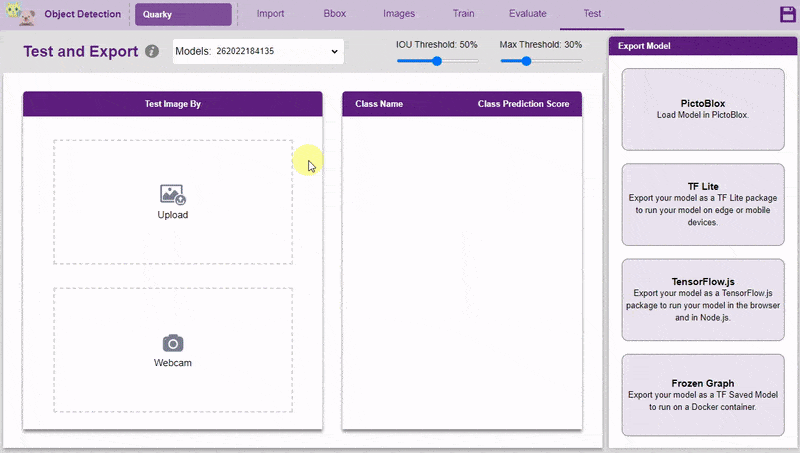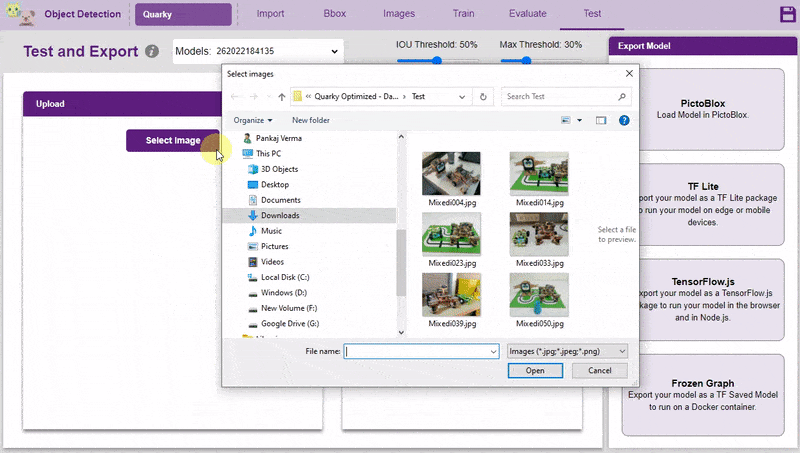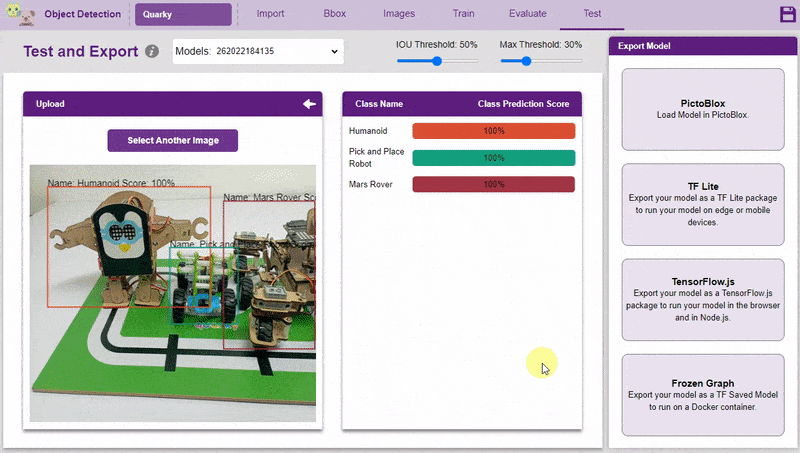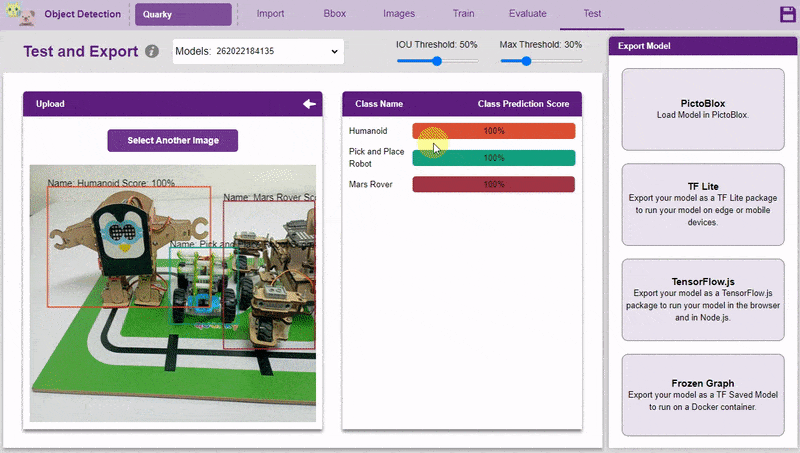
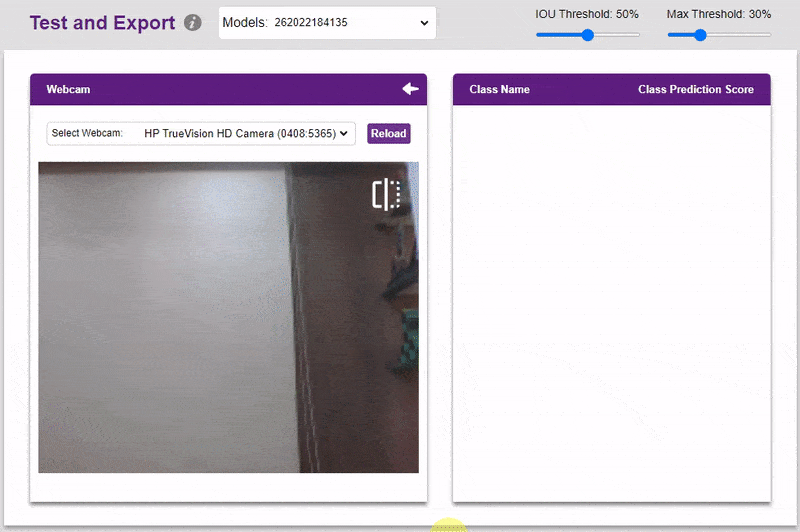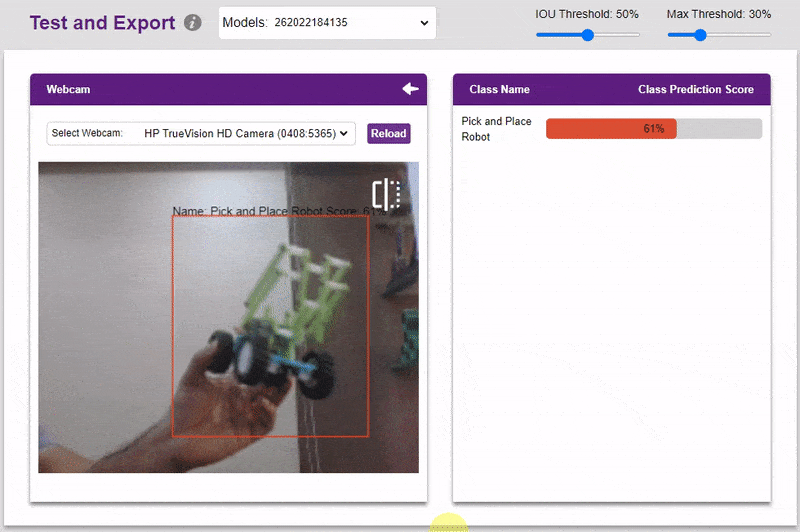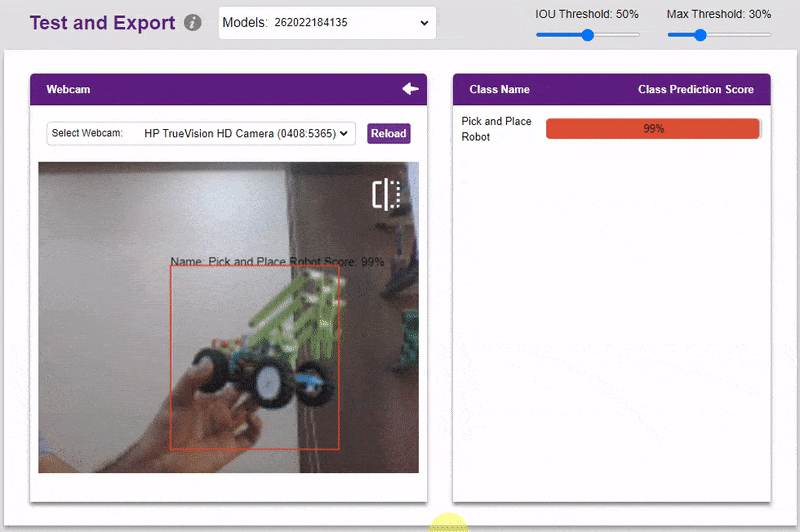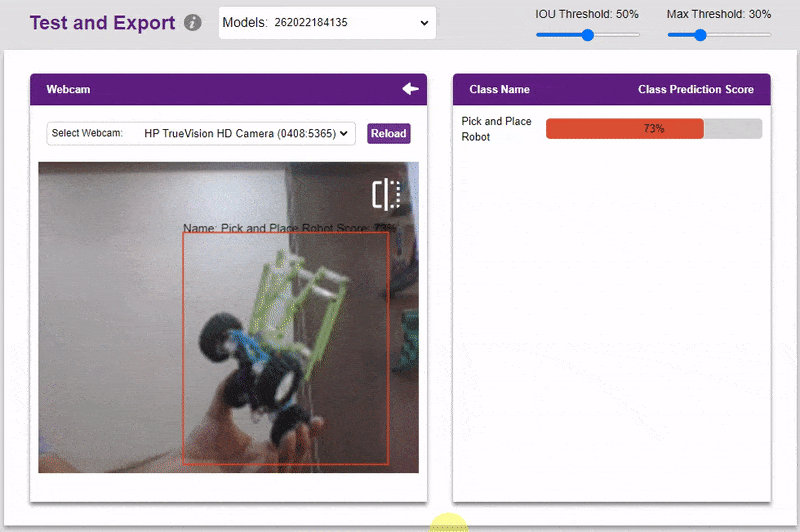
Inside the Testing tab, you can upload or capture images and see how your model performs in the given scenario.
- You can upload the image and test the model.
- You can also test the model with webcam.
Export in Python Coding
Click on the “PictoBlox” button, and PictoBlox will load your model into the Python Coding Environment.
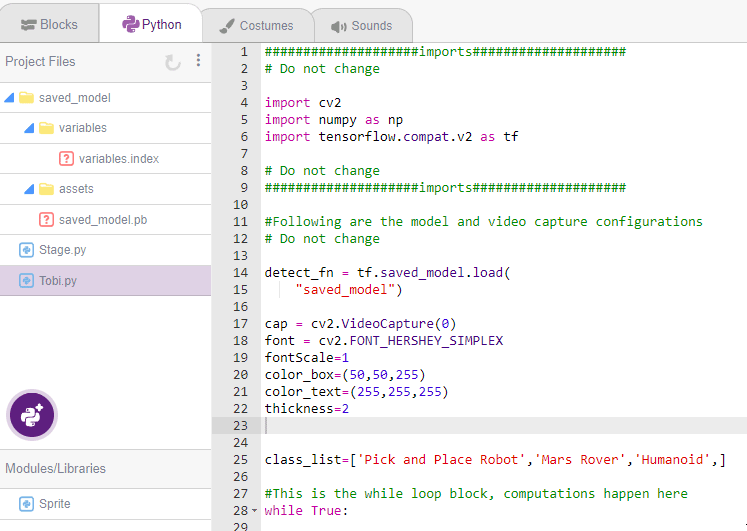
The full code looks like this:
####################imports####################
# Do not change
import cv2
import numpy as np
import tensorflow.compat.v2 as tf
# Do not change
####################imports####################
#Following are the model and video capture configurations
# Do not change
detect_fn = tf.saved_model.load(
"saved_model")
cap = cv2.VideoCapture(0) # Using device's camera to capture video
font = cv2.FONT_HERSHEY_SIMPLEX
fontScale=1
color_box=(50,50,255)
color_text=(255,255,255)
thickness=2
class_list=['Pick and Place Robot','Mars Rover','Humanoid',] # List of all the classes
#This is the while loop block, computations happen here
while True:
ret, image_np = cap.read() # Read Frame
height, width, channels = image_np.shape # Get height, wdith
image_resized=cv2.resize(image_np,(320,320)) # Resize image to model input size
input_tensor = tf.convert_to_tensor(image_resized) # Convert image to tensor
input_tensor = input_tensor[tf.newaxis, ...] # Expanding the tensor dimensions
detections = detect_fn(input_tensor) #Pass image to model
num_detections = int(detections.pop('num_detections')) #Postprocessing
detections = {key: value[0, :num_detections].numpy() for key, value in detections.items()}
detections['num_detections'] = num_detections
detections['detection_classes'] = detections['detection_classes'].astype(np.int64)
# Draw recangle around detection object
for j in range(len(detections['detection_boxes'])):
# Set minimum threshold to 0.3
if(detections['detection_scores'][j]>0.3):
# Starting and end point of detected object
starting_point=(int(detections['detection_boxes'][j][1]*width),int(detections['detection_boxes'][j][0]*height))
end_point=(int(detections['detection_boxes'][j][3]*width),int(detections['detection_boxes'][j][2]*height))
# Class name of detected object
className=class_list[detections['detection_classes'][j]-1]
# Starting point of text
starting_point_text=(int(detections['detection_boxes'][j][1]*width),int(detections['detection_boxes'][j][0]*height)-5)
# Draw rectangle and put text
image_np = cv2.rectangle(image_np, starting_point, end_point,color_box, thickness)
image_np = cv2.putText(image_np,className, starting_point_text, font,fontScale, color_text, thickness, cv2.LINE_AA)
# Show image in new window
cv2.imshow("Detection Window",image_np)
if cv2.waitKey(25) & 0xFF == ord('q'): # Press 'q' to close the classification window
break
cap.release() # Stops taking video input
cv2.destroyAllWindows() # Closes input windowHere‘s what the above Python Code is doing:
- Capturing video from the webcam.
- Resizing frame to 320x320.
- Converting frame to a tensor.
- Expanding tensor to have batch dimension.
- Passing the frame to the trained model.
- Postprocessing the results.
- Displaying the results.
Click on the run button to test the code:

Modifying the Code
Sometimes if you have to analyze an image from the file, then you have to edit the code accordingly. In this example, we are going to analyze the testing files. Follow the steps:
- We will load all the files in PictoBlox using the image upload option.
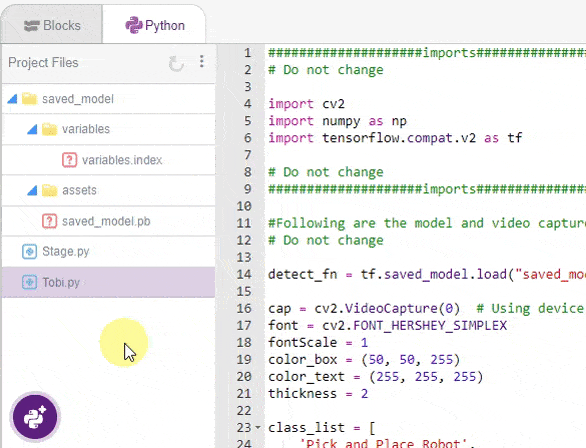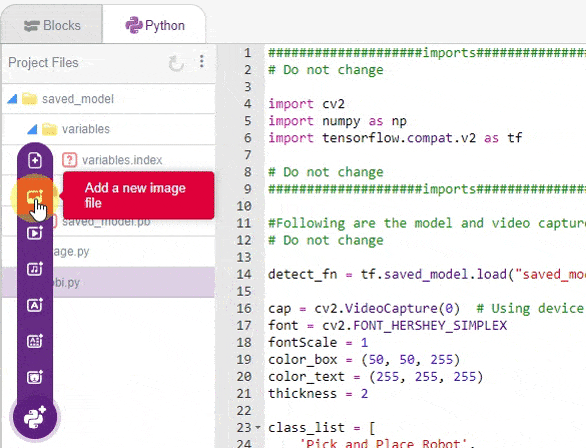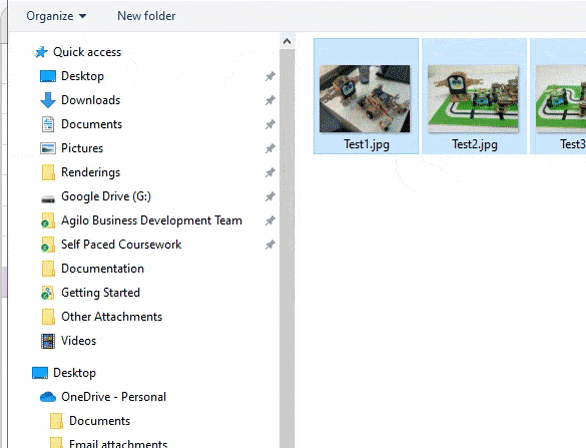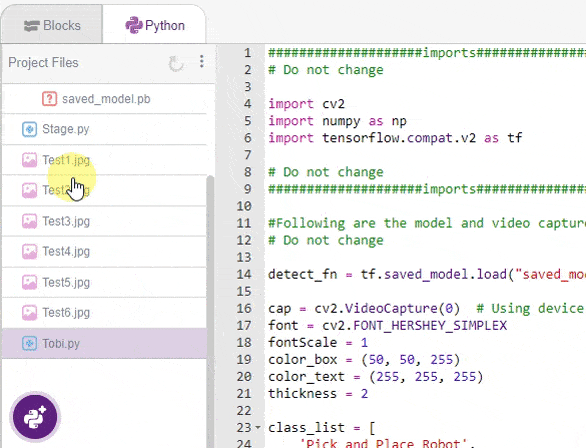
- Modify the code to do the following:
- Reading the image from the specified location and storing it in a variable called image_np.
- Resize the image to the model‘s input size.
- Then convert the image to a Tensor.
- We pass the image to the model to get the output.
- Post–processing is done to get the final results and we draw the rectangle around the detected object.
- We then save the image with the analysis.
Following is the final code:
####################imports####################
# Do not change
import cv2
import numpy as np
import tensorflow.compat.v2 as tf
# Do not change
####################imports####################
#Following are the model and video capture configurations
# Do not change
detect_fn = tf.saved_model.load("saved_model")
font = cv2.FONT_HERSHEY_SIMPLEX
fontScale = 0.6
color_box = (50, 50, 255)
color_text = (255, 255, 255)
thickness = 1
class_list = [
'Pick and Place Robot',
'Mars Rover',
'Humanoid',
] # List of all the classes
#This is the while loop block, computations happen here
for i in range(6):
image_np = cv2.imread("Test" + str(i + 1) + ".jpg", cv2.IMREAD_COLOR) # Read Frame
height, width, channels = image_np.shape
image_resized = cv2.resize(image_np,
(320, 320)) # Resize image to model input size
input_tensor = tf.convert_to_tensor(image_resized) # Convert image to tensor
input_tensor = input_tensor[tf.newaxis,
...] # Expanding the tensor dimensions
detections = detect_fn(input_tensor) #Pass image to model
num_detections = int(detections.pop('num_detections')) #Postprocessing
detections = {
key: value[0, :num_detections].numpy()
for key, value in detections.items()
}
detections['num_detections'] = num_detections
detections['detection_classes'] = detections['detection_classes'].astype(
np.int64)
# Draw recangle around detection object
for j in range(len(detections['detection_boxes'])):
# Set minimum threshold to 0.5
if (detections['detection_scores'][j] > 0.5):
# Starting and end point of detected object
starting_point = (int(detections['detection_boxes'][j][1] * width),
int(detections['detection_boxes'][j][0] * height))
end_point = (int(detections['detection_boxes'][j][3] * width),
int(detections['detection_boxes'][j][2] * height))
# Class name of detected object
className = class_list[detections['detection_classes'][j] - 1]
# Starting point of text
starting_point_text = (int(
detections['detection_boxes'][j][1] *
width), int(detections['detection_boxes'][j][0] * height) - 5)
# Draw rectangle and put text
image_np = cv2.rectangle(image_np, starting_point, end_point, color_box,
thickness)
image_np = cv2.putText(image_np, className, starting_point_text, font,
fontScale, color_text, thickness, cv2.LINE_AA)
cv2.imwrite("Image " + str(i + 1) + " Analysed.jpg", image_np)
You will get the following results:
