Introduction
Numbers(C/R) is the extension of the ML Environment that deals with the classification and regression of numeric data. In this tutorial, we’ll be looking at Numeric Classification with the help of the “Titanic Dataset” in the PictoBlox Python Coding Environment.
Titanic Challenge
The sinking of the Titanic is one of the most infamous shipwrecks in history.

On April 15, 1912, during her maiden voyage, the widely considered “unsinkable” RMS Titanic sank after colliding with an iceberg. Unfortunately, there weren’t enough lifeboats for everyone onboard, resulting in the death of 1502 out of 2224 passengers and crew.
While there was some element of luck involved in surviving, it seems some groups of people were more likely to survive than others.
In this tutorial, we will build a predictive model that answers the question: “what sorts of people were more likely to survive?” using passenger data (ie name, age, gender, socio-economic class, etc).
Titanic Dataset
The Titanic dataset contains information about the passengers on the ship and whether they survived the sinking of the ship or not. The target column is titled “Survived” and it consists of binary values.
- Value “1” denotes that the passenger survived.
- Value “0” denotes that the passenger did not survive.
Download the dataset here:
- Training Data: titanic_train
- Testing Data: titanic_test
Let’s start!
Setting up the Environment
First, we need to set the ML environment for Number classification.

Follow the steps below:
- Open PictoBlox and create a new file.
- Select the coding environment as Python Coding.
- To access the ML Environment, select the “Open ML Environment” option under the “Files” tab.
- You’ll be greeted with the following screen.
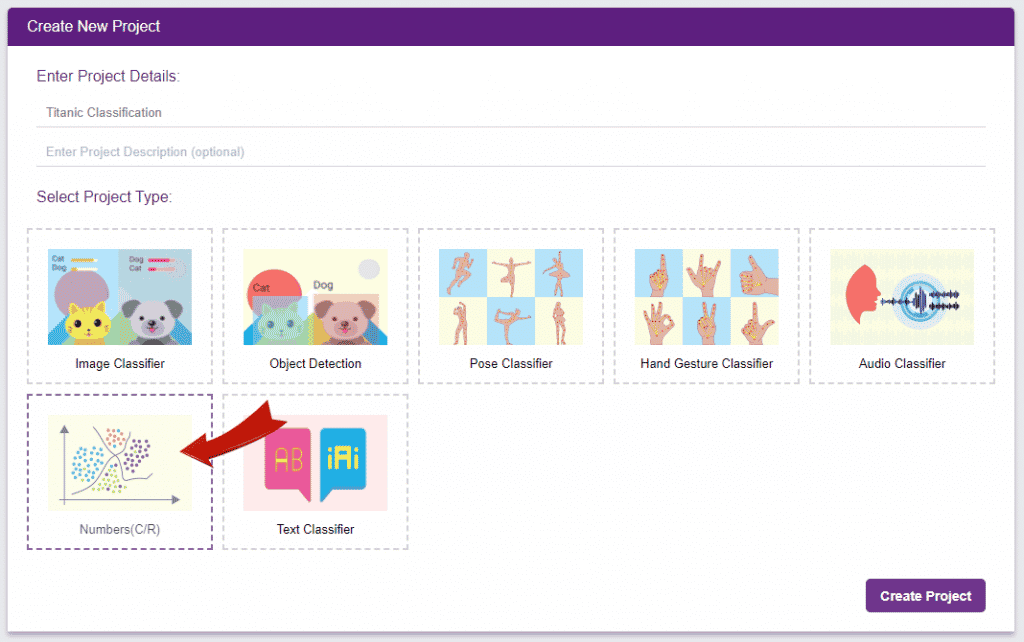
 Click on “Create New Project“.
Click on “Create New Project“. - A window will open. Type in a project name of your choice and select the “Numbers(C/R)” extension. Click the “Create Project” button to open the Numbers(C/R) window.
- You shall see the Numbers C/R workflow with an option to either “Upload Dataset” or “Create Dataset”.
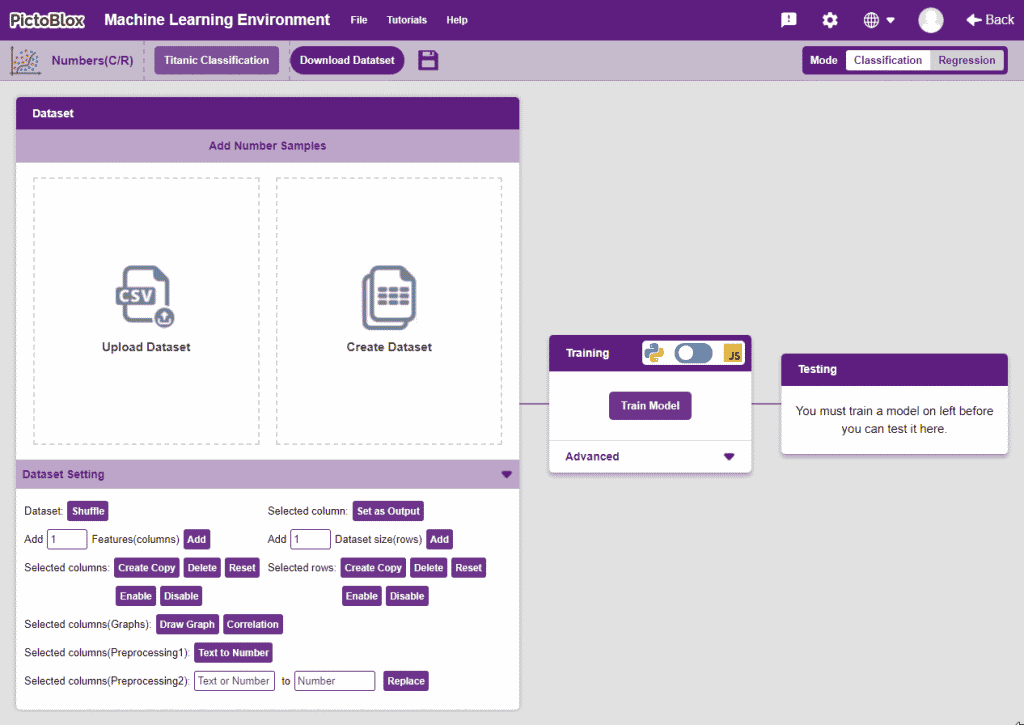
Uploading/Creating the Dataset
- Click on “Upload Dataset”, and then on “Choose CSV from your files”.
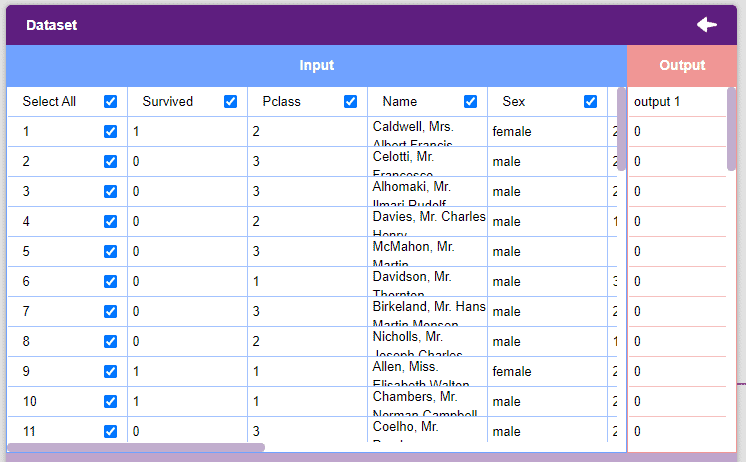
- Select the “titanic_train.csv” file of the Titanic dataset. This is how your data will look.
 Note: For our model to train, it is important that we only feed it numerical values. Hence, we must pre-process our data accordingly. Thankfully, the PictoBlox ML Environment comes with all the necessary tools to modify our data.
Note: For our model to train, it is important that we only feed it numerical values. Hence, we must pre-process our data accordingly. Thankfully, the PictoBlox ML Environment comes with all the necessary tools to modify our data. - Let’s analyze the data pre-processing features for a minute. Observe the “Data Settings”.
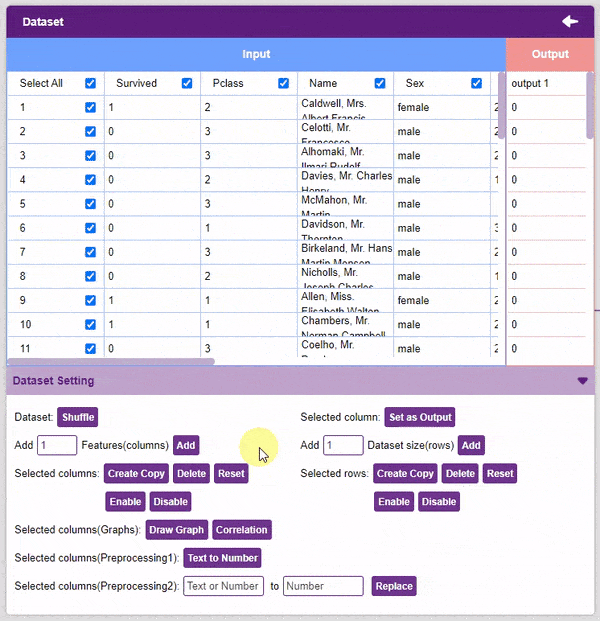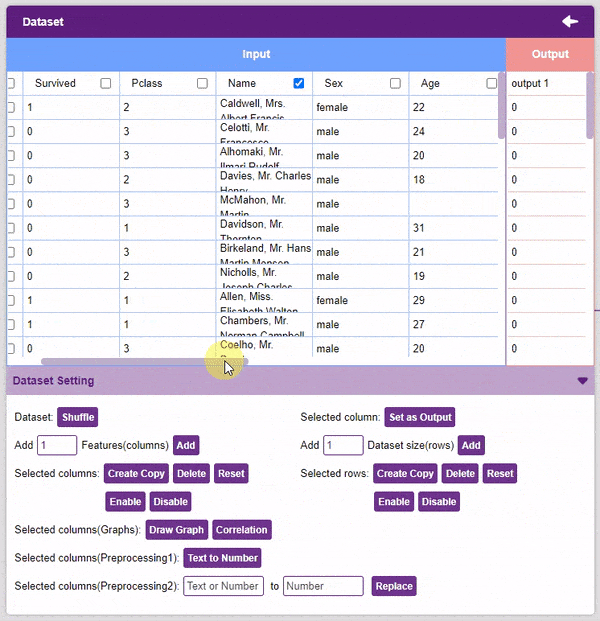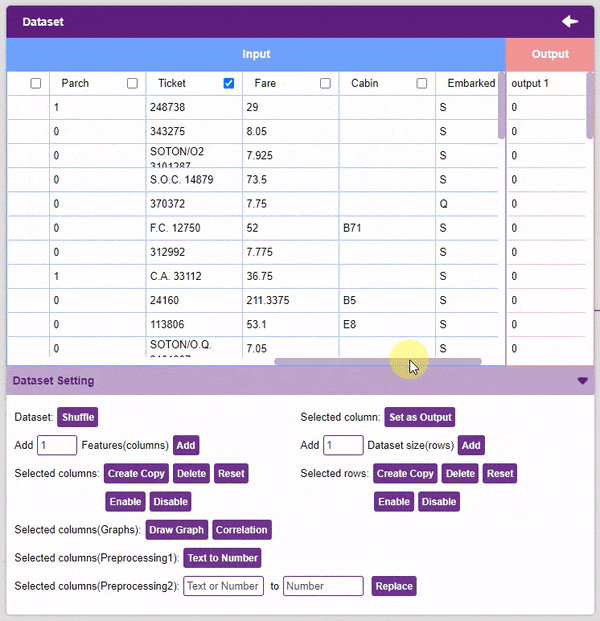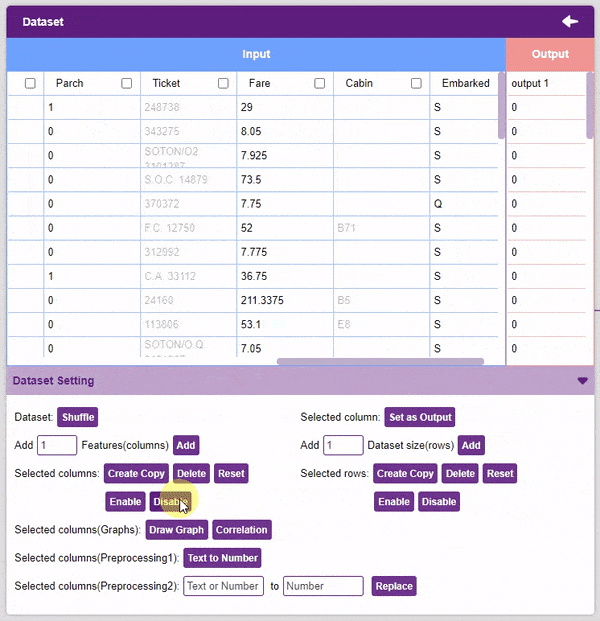
- We will be dropping the “Name”, “Ticket”, and “Cabin” columns.
- Now we will convert the columns “Sex”, and “Embarked” into numeric values using the Text to Number button.
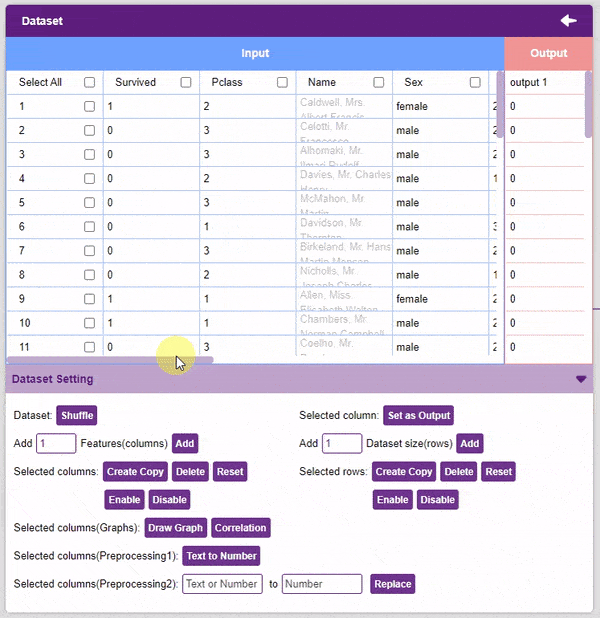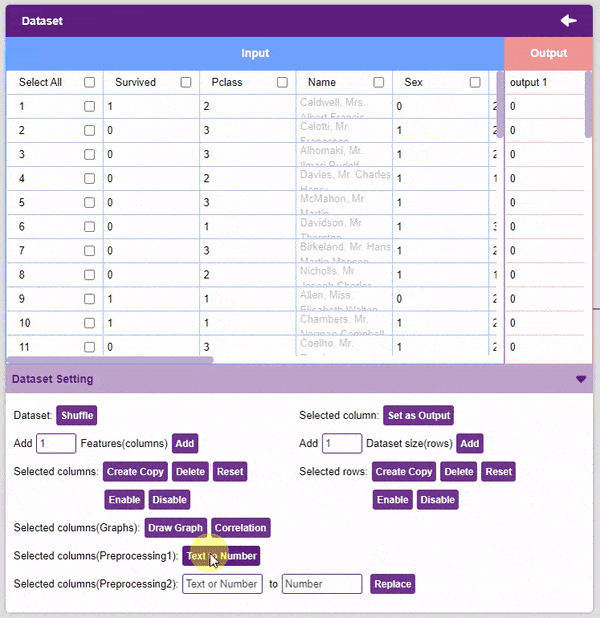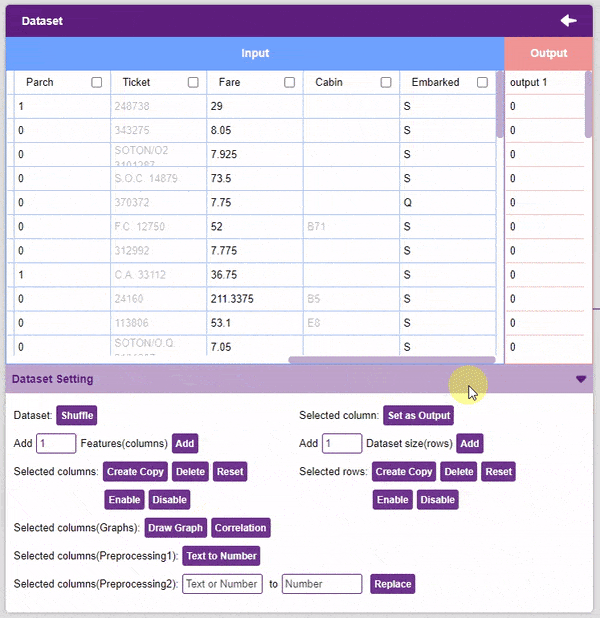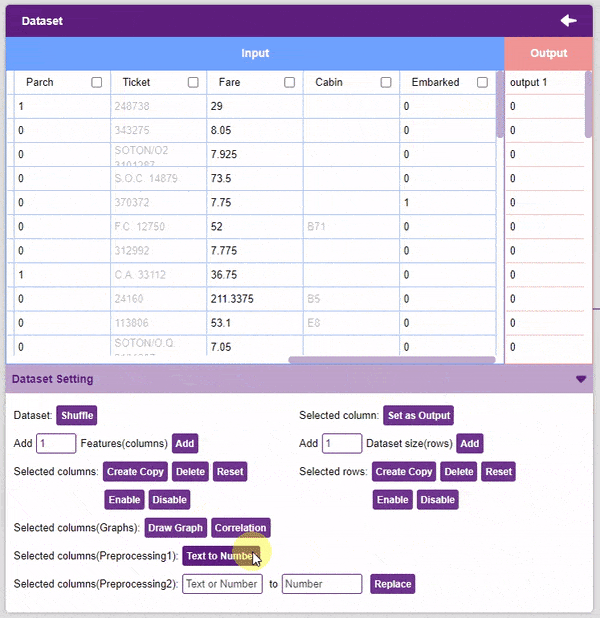 Note: The “Text to Number” button assigns a number to all the unique values. If a column has three unique values, they will be assigned corresponding numbers starting with 0. Hence, the values in the case of three unique values would be 0, 1, and 2.
Note: The “Text to Number” button assigns a number to all the unique values. If a column has three unique values, they will be assigned corresponding numbers starting with 0. Hence, the values in the case of three unique values would be 0, 1, and 2. - Our target column in this project is the “Survived” column. To set it as the output column, select it and click on the Set as Output button.
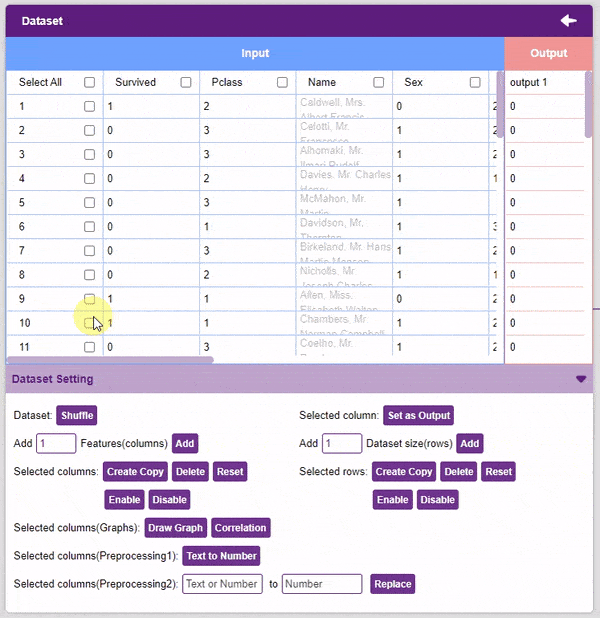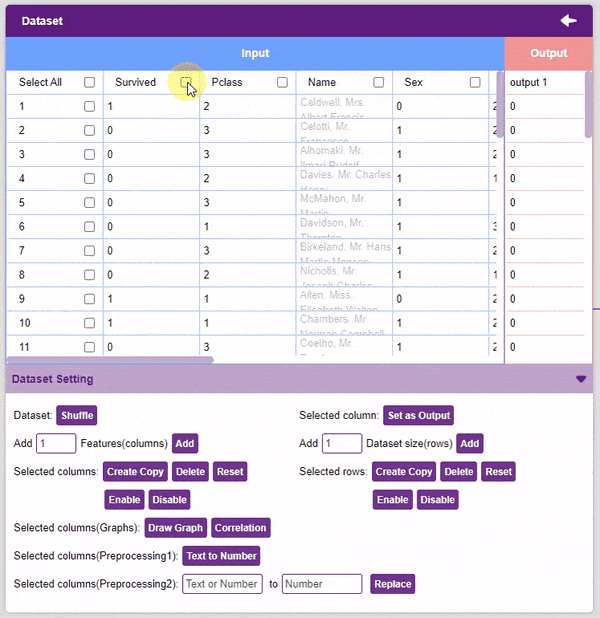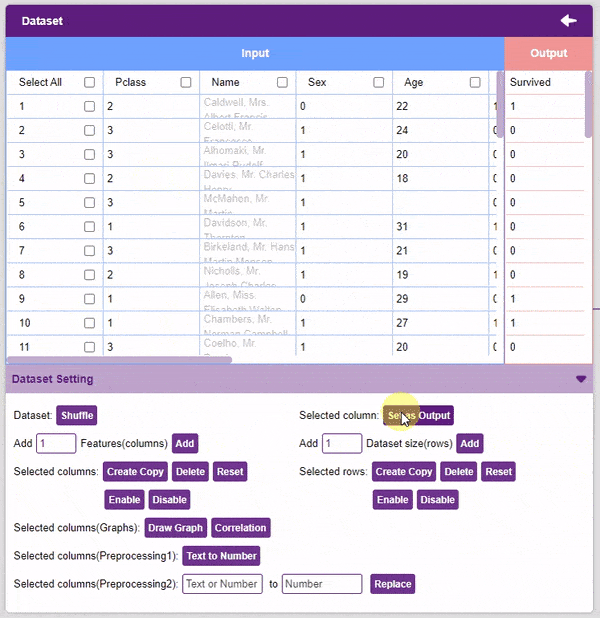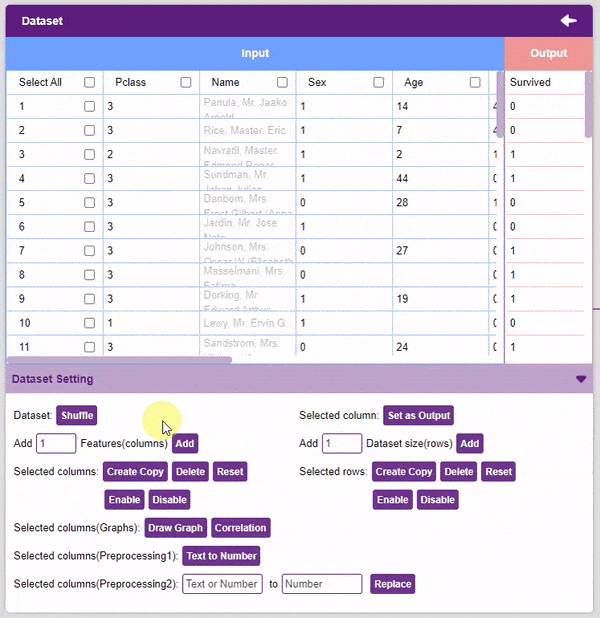
Our dataset is ready! Time to train the model.
Training the Model
Now that we have gathered the data, it’s time to teach our model how to classify new, unseen data into these classes. To do this, we have to train the model.

By training the model, we extract meaningful information from the data, and that in turn updates the weights. Once these weights are saved, we can use our model to make predictions on data previously unseen.
However, before training the model, there are a few hyperparameters that you should be aware of. Click on the “Advanced” tab to view them.
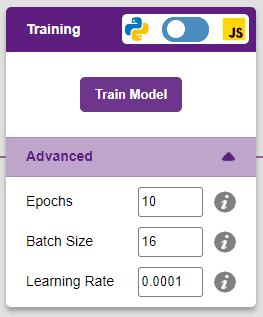
There are three hyperparameters you can play along with here:
- Epochs– The total number of times your data will be fed through the training model. Therefore, in 10 epochs, the dataset will be fed through the training model 10 times. Increasing the number of epochs can often lead to better performance.
- Batch Size– The size of the set of samples that will be used in one step. For example, if you have 160 data samples in your dataset, and you have a batch size of 16, each epoch will be completed in 160/16=10 steps. You’ll rarely need to alter this hyperparameter.
- Learning Rate– It dictates the speed at which your model updates the weights after iterating through a step. Even small changes in this parameter can have a huge impact on the model performance. The usual range lies between 0.001 and 0.0001.
You can train the model in both JavaScript and Python. To choose between the two, click on the switch on top of the Training box.
We’ll be training this model in Python. Click on the “Train Model” button to commence training. It’s a good idea to use a high number of epochs for this model. We’ll be training this model for 120 epochs.
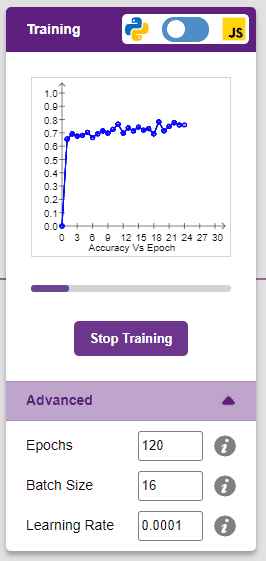
The model shows great results! Remember, the higher the reading in the accuracy graph, the better the model. The x-axis of the graph shows the epochs, and the y-axis represents the corresponding accuracy. The range of the accuracy is 0 to 1.
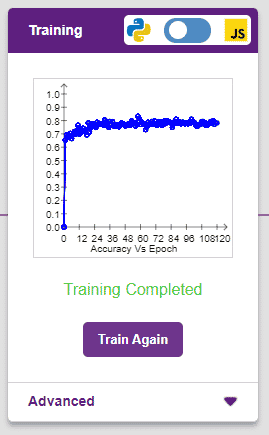
Testing the Model
Now that the model is trained, let us see if it delivers the expected results. For that, we simply need to input values and click on the “Predict” button.
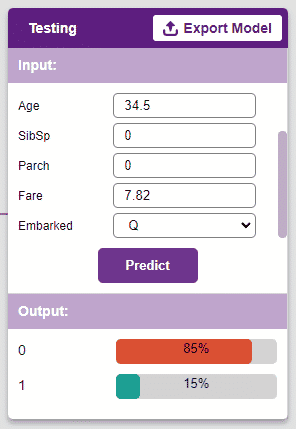
Great! Time to export this model to PictoBlox and create a script.
Exporting the Model to the Python Coding
Click on the “Export Model” button on the top right of the Testing box, and PictoBlox will load your model into the Python Coding Environment.
Observe that have created a python testing code already for you.
Click on Beautify Button to make the code error-free of any indentation errors. It’s the left icon from the A+ (Magic Wand).

Following is the code which is created by PictoBlox.
####################imports####################
# Do not change
import numpy as np
import tensorflow as tf
# Do not change
####################imports####################
#Load Number Model
# Do not change
model = tf.keras.models.load_model("num_model.h5",
custom_objects=None,
compile=True,
options=None)
###############################################
#Inputs
Pclass = 0
Sex = 0
Age = 0
SibSp = 0
Parch = 0
Fare = 0
Embarked = 0
###############################################
# Do not change
class_list = [
'0',
'1',
] # List of all the classes
inputValue = [
Pclass,
Sex,
Age,
SibSp,
Parch,
Fare,
Embarked,
] # Input List
inputTensor = tf.expand_dims(inputValue, 0) # Input Tensor
predict = model.predict(
inputTensor) # Making an initial prediction using the model
predict_index = np.argmax(predict[0],
axis=0) # Generating index out of the prediction
predicted_class = class_list[
predict_index] # Tallying the index with class list
print(predicted_class)
The code uses two libraries:
- Numpy – For array manipulation
- Tensorflow – For machine learning
Add the data in the input for testing. You can use the “test.csv“.
###############################################
#Inputs
Pclass = 3
Sex = 1
Age = 34.5
SibSp = 0
Parch = 0
Fare = 7.8292
Embarked = 1Click on the Run button to run and test the code.
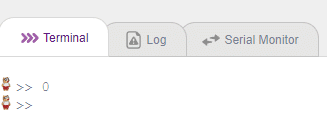
You will see the output in the Terminal.
Prediction of Multiple Cases with CSV
Let’s see how you can run the bulk prediction on the titanic_test.csv file. For this, we have to use loops and Pandas library. Lets start:
Import the titanic_test.csv CSV file to the PictoBlox project.
You will get this:
Next, we will modify the code. The full code is provided below:
####################imports####################
# Do not change
import numpy as np
import tensorflow as tf
import pandas as pd
# Do not change
####################imports####################
#Load Number Model
# Do not change
model = tf.keras.models.load_model("num_model.h5",
custom_objects=None,
compile=True,
options=None)
class_list = [
'0',
'1',
] # List of all the classes
test_data = pd.read_csv('titanic_test.csv')
test_data_output = pd.DataFrame()
print(len(test_data.index))
for i in range(len(test_data.index)):
#Inputs
Pclass = test_data.loc[i].at["Pclass"]
Sex = test_data.loc[i].at["Sex"]
if Sex == 'female':
Sex = 0
else:
Sex = 1
Age = test_data.loc[i].at["Age"]
SibSp = test_data.loc[i].at["SibSp"]
Parch = test_data.loc[i].at["Parch"]
Fare = test_data.loc[i].at["Fare"]
Embarked = test_data.loc[i].at["Embarked"]
if Embarked == 'S':
Embarked = 0
elif Embarked == 'Q':
Embarked = 1
else:
Embarked = 2
inputValue = [
Pclass,
Sex,
Age,
SibSp,
Parch,
Fare,
Embarked,
] # Input List
inputTensor = tf.expand_dims(inputValue, 0) # Input Tensor
predict = model.predict(
inputTensor) # Making an initial prediction using the model
predict_index = np.argmax(predict[0],
axis=0) # Generating index out of the prediction
predicted_class = class_list[
predict_index] # Tallying the index with class list
if predicted_class == "0":
test_data_output = test_data_output.append({"PassengerID" : test_data.loc[i].at["PassengerId"], "Result" : "Did Not Survived", "Confidence" : predict[0][0]}, ignore_index = True)
else:
test_data_output = test_data_output.append({"PassengerID" : test_data.loc[i].at["PassengerId"], "Result" : "Survived", "Confidence": predict[0][1]}, ignore_index = True)
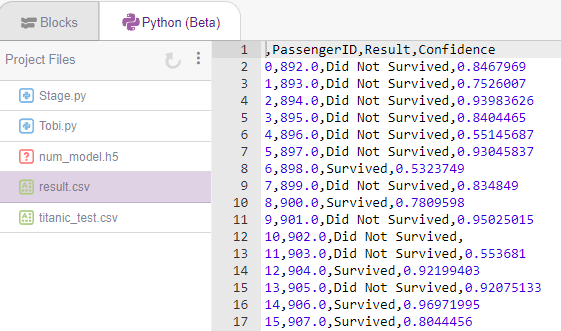
test_data_output.to_csv("result.csv")
You will find the result in an additional file created with the name “results.csv“.