Introduction to Audio Classifier
The Audio Classifier is the extension of the PictoBlox Machine Learning Environment that deals with the classification of audio and speech data.
In this tutorial, we’ll be making a project to control Tobi’s movement using snaps and taps. For this project, we’ll be needing three classes:
- Snap
- Tap
- Background
These are the steps involved in the procedure:
- Setting up the environment
- Gathering the data (Data collection)
- Training the model
- Testing the model
- Exporting the model to PictoBlox
- Creating a script in PictoBlox
Setting up the Environment
First, we need to set the ML environment for audio classification.

Follow the steps below:
- Open PictoBlox and create a new file.
- Select the coding environment as Block Coding.
- To access the ML Environment, select the “Open ML Environment” option under the “Files” tab.
- You’ll be greeted with the following screen.
 Click on “Create New Project“.
Click on “Create New Project“. - A window will open. Type in a project name of your choice and select the “Audio Classifier” extension. Click the “Create Project” button to open the Audio Classifier window.
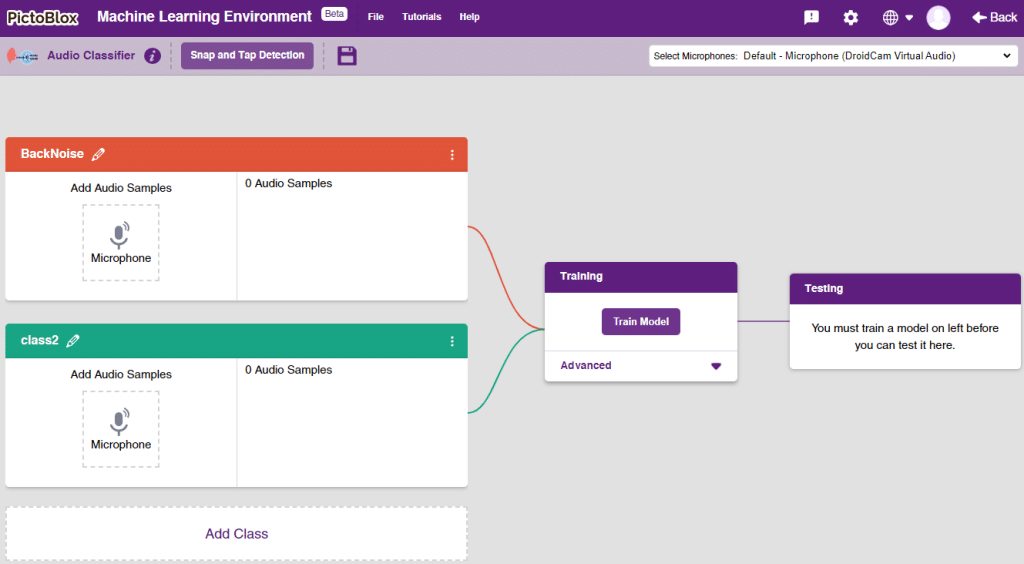
- You shall see the Audio Classifier Workflow with two classes already made for you. Your environment is all set. Now it’s time to upload the data.
Collecting and Uploading the Data
Class is the category in which the Machine Learning model classifies the audio. Similar audio is put in one class.

There are 2 things that you have to provide in a class:
- Class Name
- Audio Data: This data can either be taken from the microphone.
Follow the steps to upload the data for the classes:
- Rename the second class name Snap and add another class with the name Tap.
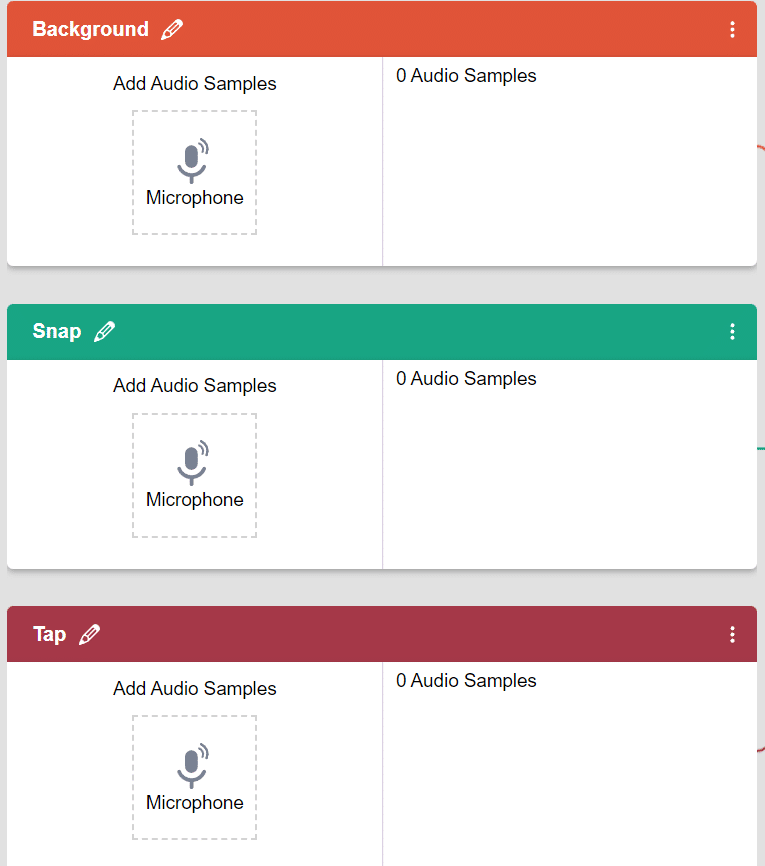
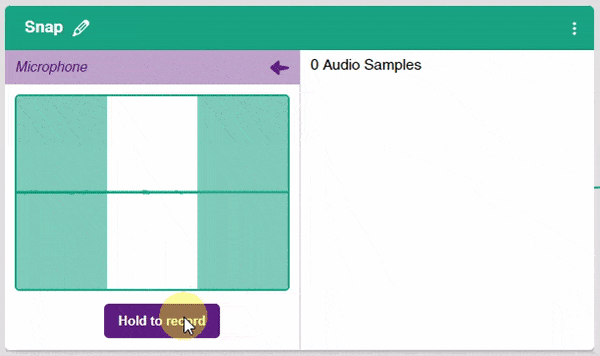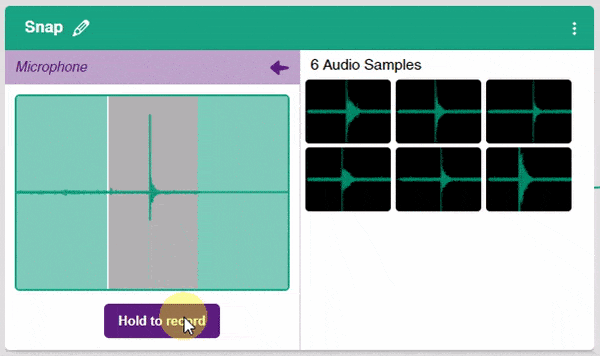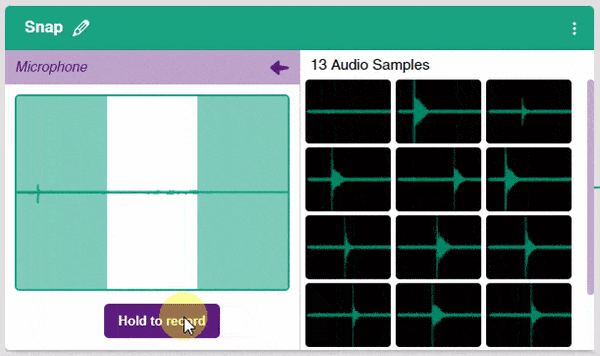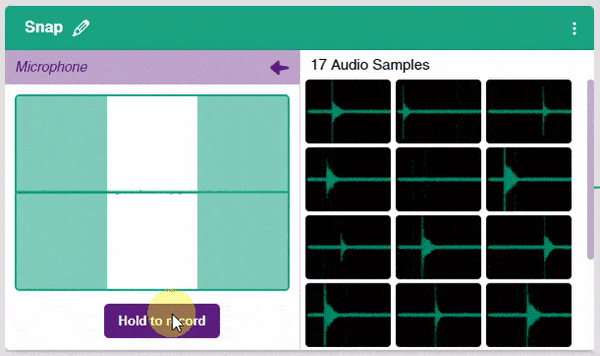
- In the Audio Classifier, you can add samples by using your device’s microphone. Click on the “Microphone” button to record samples. The “Background” class will simply contain the background noise samples.
Note: Samples are recorded in a 1-second burst.
- Record samples for all three classes.
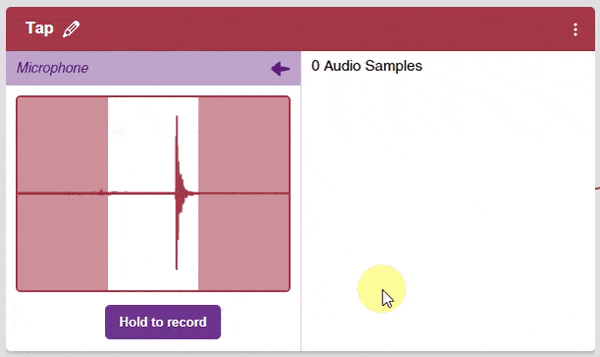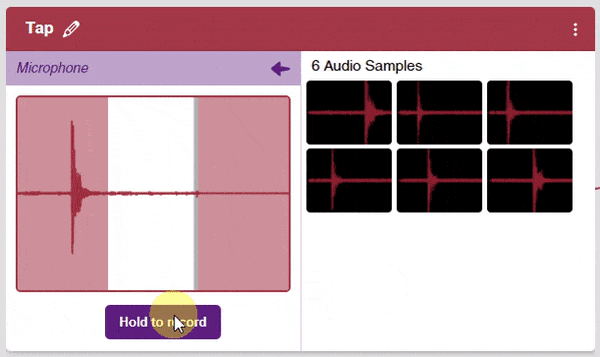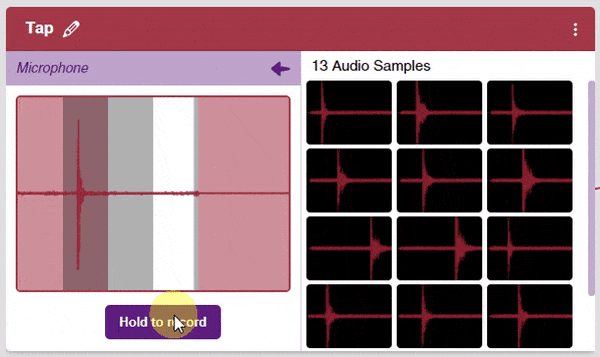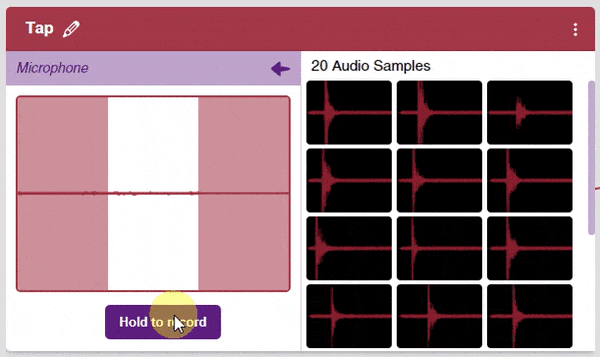 Note: You must add at least 20 samples to each of your classes for your model to train. More samples will lead to better results.
Note: You must add at least 20 samples to each of your classes for your model to train. More samples will lead to better results.
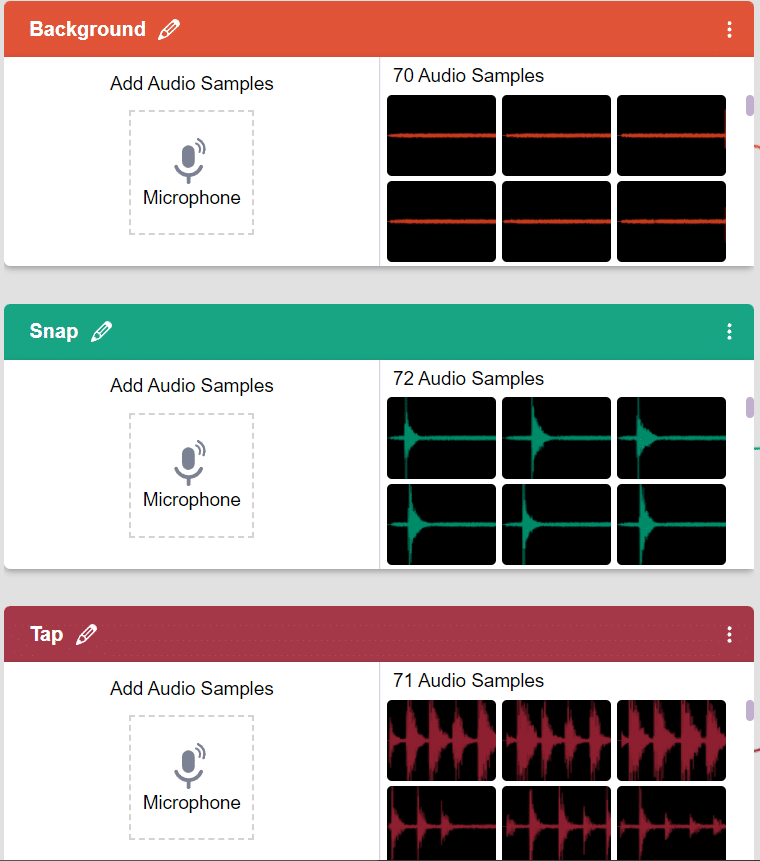
As you can see, now each class has some data to derive patterns from. In order to extract and use these patterns, we must train our model.
Training the Model
Now that we have gathered the data, it’s time to teach our model how to classify new, unseen data into these three classes. In order to do this, we have to train the model. By training the model, we extract meaningful information from the images, and that in turn updates the weights. Once these weights are saved, we can use our model to make predictions on data previously unseen.
However, before training the model, there are a few hyperparameters that you should be aware of. Click on the “Advanced” tab to view them.
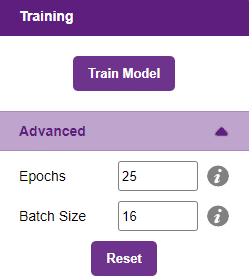
There are two hyperparameters you can play along with here:
- Epochs– The total number of times your data will be fed through the training model. Therefore, in 10 epochs, the dataset will be fed through the training model 10 times. Increasing the number of epochs can often lead to better performance.
- Batch Size– The size of the set of samples that will be used in one step. For example, if you have 160 data samples in your dataset, and you have a batch size of 16, each epoch will be completed in 160/16=10 steps. You’ll rarely need to alter this hyperparameter.
We’ll be training this model in JavaScript. Click on the “Train Model” button to commence training. We need not change any hyperparameter for this model.
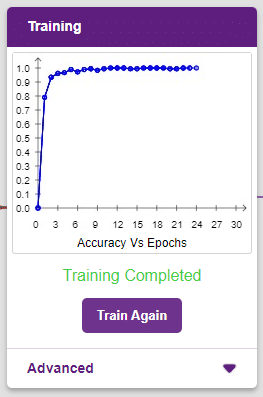
The model shows great results! Remember, the higher the reading in the accuracy graph, the better the model. The x-axis of the graph shows the epochs, and the y-axis represents the corresponding accuracy. The range of the accuracy is 0 to 1.
Testing the Model
Now that the model is trained, let’s see if it delivers the expected results. We can test our model by using our device microphone.
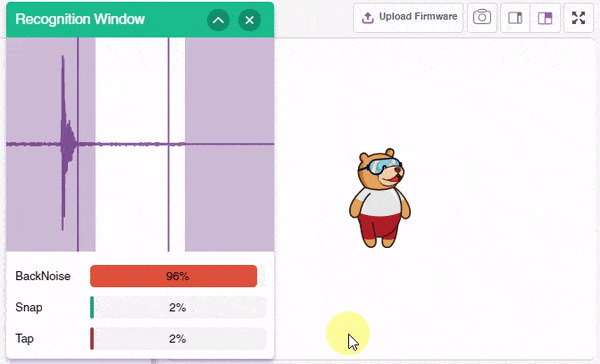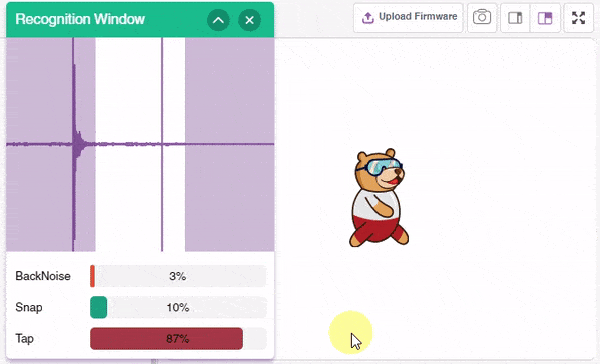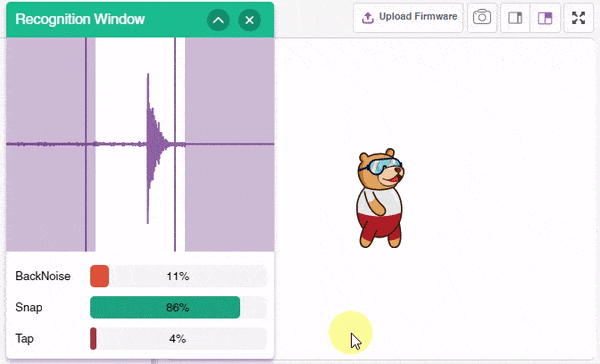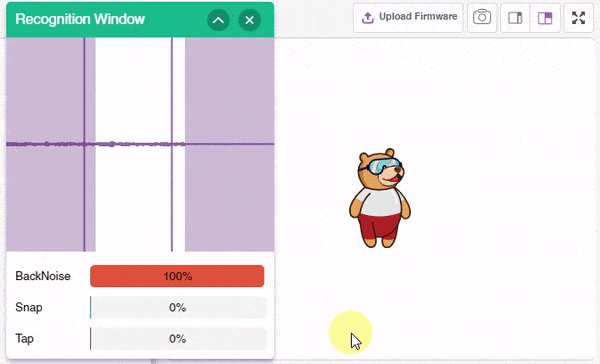
Click on the “Microphone” option in the testing box and the model will start predicting based on the audio input.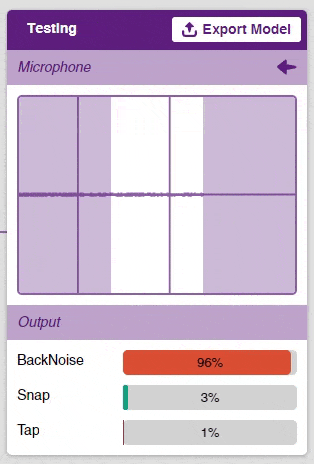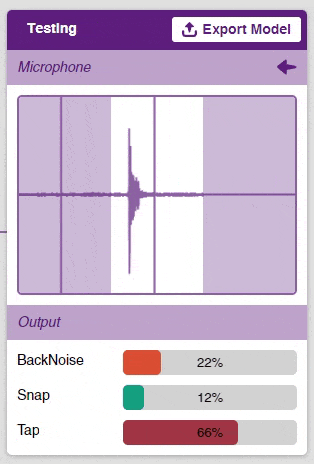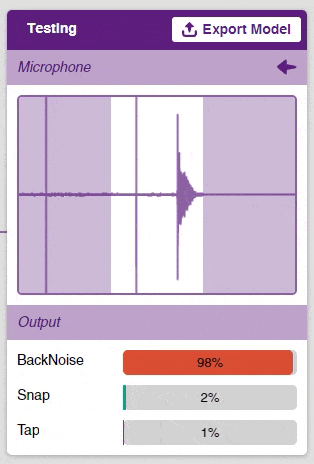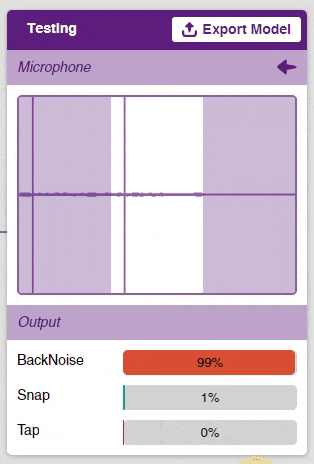
Great! The model is able to make predictions in real-time. Now, let’s export this model to PictoBlox and write a script in block coding.
Exporting the Model to the Block Coding Environment
Click on the “Export Model” button on the top right of the Testing box, and PictoBlox will load your model into the Block Coding Environment.
Writing the Script in the Block Coding
Now let’s use our model in an actual project. To do so, we’ll be making use of our Block Coding Environment.
We’ll be making a script that uses our model to analyze an audio sample from our device’s microphone. Once that’s done, our sprite Tobi will change the costume as per our instructions.
- We’ll start by adding a when flag clicked block from the Events palette.
- Follow it up with an open recognition window block from the Machine Learning palette.
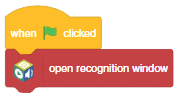
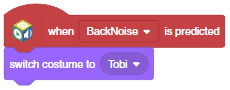
- Now drag a when () is predicted block from the Machine Learning palette. Select the class as BackNoise.
- Below the block, add a switch costume to () block from the Looks palette. Select the costume as Tobi.
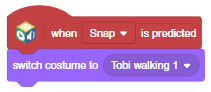
- Repeat the same for Snap. Select the costume as Tobi Walking 1.
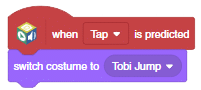
- Repeat the same for Tap. Select the costume as Tobi Jump.
Click on the green flag to test the script.
There you go! Tobi will change his costume according to the sounds you make.